Wir stellen in diesem Artikel eine Reihe von Metriken vor, mit denen unterschiedliche Verfahren und trainierte Modelle für Klassifizierungsprobleme verglichen und bewertet werden können. In unserem Artikel Machine Learning Klassifizierung in Python – Teil 1: Data-Profiling und Vorverarbeitung stellen wir unterschiedliche Klassifizierungsverfahren vor, deren Performance mit den hier beschriebenen Metriken verglichen werden können.
Die Fälle im Detail
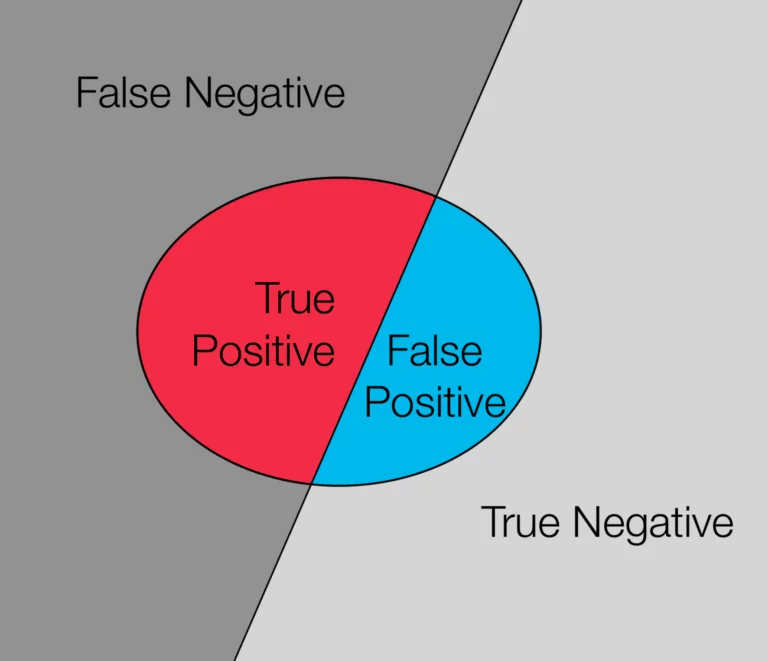
Diese Fälle beziehen sich alle auf das vorhergesagte Target eines zu klassifizierenden Objekts. Nachfolgend listen wir dabei alle Fälle zusammen mit ihrer Bedeutung auf.
- False Negative: Der Fall eines falscherweise nicht als Treffer klassifizierten Targets eines Objekts.
- False Positive: Der Fall eines falsch als Treffer klassifizierten Targets eines Objekts.
- True Negative: Der Fall eines richtig nicht als Treffer eines klassifizierten Targets eines Objekts.
- True Positive: Der Fall eines richtig als Treffer klassifizierten Targets eines Objekts.
Beispiel: Fluggastdatenweitergabe an das BKA
Um die Begriffe noch einmal zu verdeutlichen, schauen wir uns einen Artikel zur Weitergabe von Fluggastdaten an das Bundeskriminalamt (BKA) der SZ vom 24. April 2019 an. Seit dem 29. August 2018 wurden Daten von Fluggästen automatisch an das BKA zur Auswertung übermittelt. Mit diesen Daten sollen gesuchte Straftäter und Verdächtige identifiziert werden. Die Daten bestehen aus Namen, Anschrift, Zahlungsdaten und Flugdaten, wie Reisedatum, Uhrzeit, Start- und dem Zielflughafen des Reisenden und werden im Passenger Name Record gespeichert.
This data is to be used to identify wanted offenders and suspects. In the future, this data will not only be used to identify criminals but will also be used in predictive policing. Predictive policing is the analysis of past crimes to calculate the probabilities of future crimes. The aim is to identify patterns, such as the burglary rate in a residential area, in order to be able to deploy police forces in a more targeted manner.
False Positives bei großen Datenmengen
Seit Beginn der Erfassung bis zum 31. März 2019 wurden insgesamt 1,2 Mio. Fluggastdaten übergeben. Von diesen hat ein Algorithmus 94.098 Flugreisende als potenziell verdächtig klassifiziert. Alle Treffer werden anschließend von Beamten auf ihre Richtigkeit geprüft. Dabei stellte sich heraus, dass von diesen Treffern lediglich 277 echte Treffer (True Positive) waren. Bei den übrigen 93.821 klassifizierten Verdächtigen handelte es sich um falsche Treffer (False Positives). Die Reisenden aus der verbleibenden Menge die falscher Weise nicht als Verdächtige klassifiziert wurden, lassen sich in der Regel nicht genau ermitteln (False Negative). Der Rest der Daten, die richtigerweise nicht als Treffer klassifiziert wurden, ergeben die True Negatives.
Der Artikel kritisiert dabei die hohe Quote an False Positives. Denn dadurch würden häufig Menschen zu unrecht ins Visier von Behörden geraten, in diesem Fall nämlich 99,71% aller Treffer. Dabei ist jedoch zu erwähnen, dass durch eben diese hohe Fehlerrate die Wahrscheinlichkeit für False Negative Fälle sinkt. Das heißt, dass auf Kosten vieler Fehltreffer, nur wenige Zielpersonen nicht getroffen werden.
Häufig verwendete Performancemetriken
Anhand der Anzahl der aufgetretenen Fälle können wir einen Klassifikator unter verschiedenen Metriken betrachten und bewerten. In unserem Beitrag haben wir uns dafür entschieden die folgenden Metriken zu verwenden:
Precision
Eine sehr einfache Metrik ist die Precision. Diese gibt das Verhältnis an, wie viele Objekte ein Klassifikator aus dem Testdatensatz richtig als positiv klassifiziert hat, zu denen die falsch als positiv klassifiziert wurden. Die Formel lautet:
(True Positives) / (True Positives + False Positives)
Problematisch ist diese Metrik besonders bei einer binären Klassifikation, bei der eine Klasse im Beispieldatensatz überrepräsentiert wird: Der Klassifikator kann einfach alle Objekte des Datensatzes der überrepräsentierten Klasse zuordnen, würde aber dennoch eine relativ hohe Precision erreichen.
An dem Beispiel der Fluggastdaten berechnet sich die Precision wie folgt:
277 / (277 + 93.821) = 0,29%Recall
Im Gegensatz zur Precision, gibt der Recall Score, auch Trefferquote genannt, den Anteil der richtig als positiv klassifizierten Objekte an der Gesamtheit der positiven Objekte an. Das heißt wir erhalten ein Maß zur Bestimmung, wieviele positive Targets als solche erkannt werden. Die Formel lautet:
(True Positives) / (True Positives + False Negatives)
F-Score
Die F-Score setzt Precision und Recall zusammen, um eine möglichst gute Einschätzung darüber zu erhalten, wie genau die Targets der Objekte bestimmt werden.
Dabei berechnet sich der F-Score über das harmonische Mittel mit der Formel:
F = 2 * (Precision * Recall) / (Precision + Recall)
Da wir keine Informationen zu den False Negatives in unserem Beispiel haben, ist es uns nicht möglich, Recall und F-Score zu bestimmen. In unserem Artikel verfügen wir hingegen über diese Information, und können beide Kennzahlen berechnen.
Fortgeschrittene Metriken – Receiver Operating Characteristic
Als letzte Metrik verwenden wir die Receiver Operating Characteristic Kurve. Diese gibt an, wie sicher der Klassifikator seine Ergebnisse erzielt. Dabei wird das Verhältnis der Trefferquote zu den False Positive klassifizierten Daten in Abhängigkeit eines Schwellenwerts in einem Graphen dargestellt.
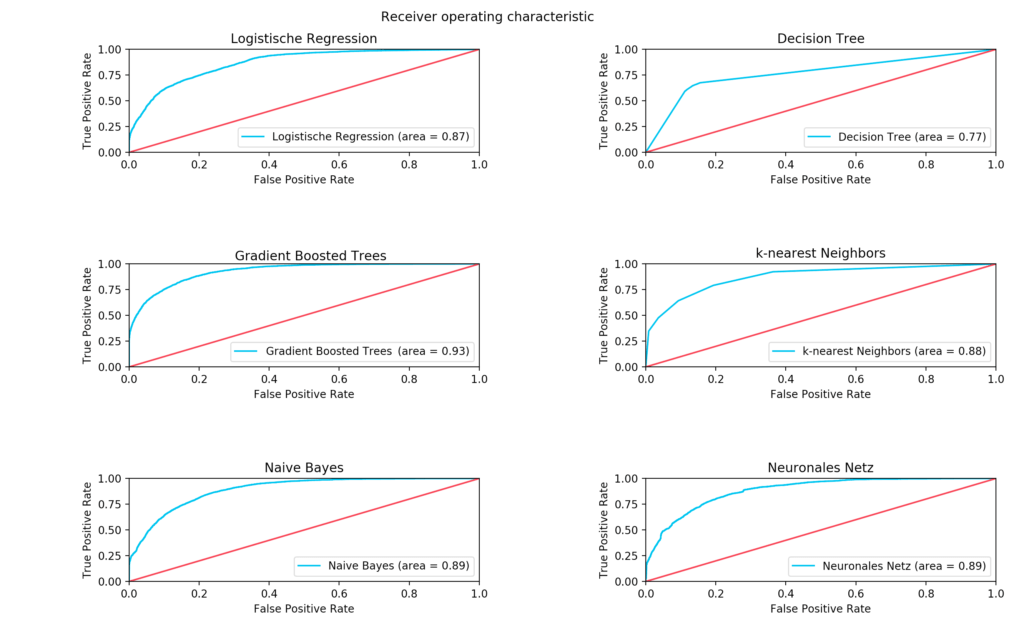
Dieser Schwellenwert gibt an, ab wann ein Objekt zur einen oder zur anderen Klasse zugeordnet wird. Dabei ist der Schwellenwert in der linken unteren Ecke des Graphen am größten, das heißt, dass das Modell das Target eines Objekts nur dann als positiv bewertet, wenn ein Objekt mit absoluter Sicherheit dem Target zugehörig ist. Demnach geht die False Positive Rate hier stark gegen 0. Je weiter man sich der rechten oberen Ecke annähert, desto geringer wird der Schwellenwert und desto wahrscheinlicher wird es, dass das Modell ein Objekt fälschlicherweise als positiv klassifiziert, obwohl es eigentlich negativ war (False Positive). Die Fläche unter dem Graphen (Area under curve) dient also als Metrik für die Qualität eines getesteten Modells.
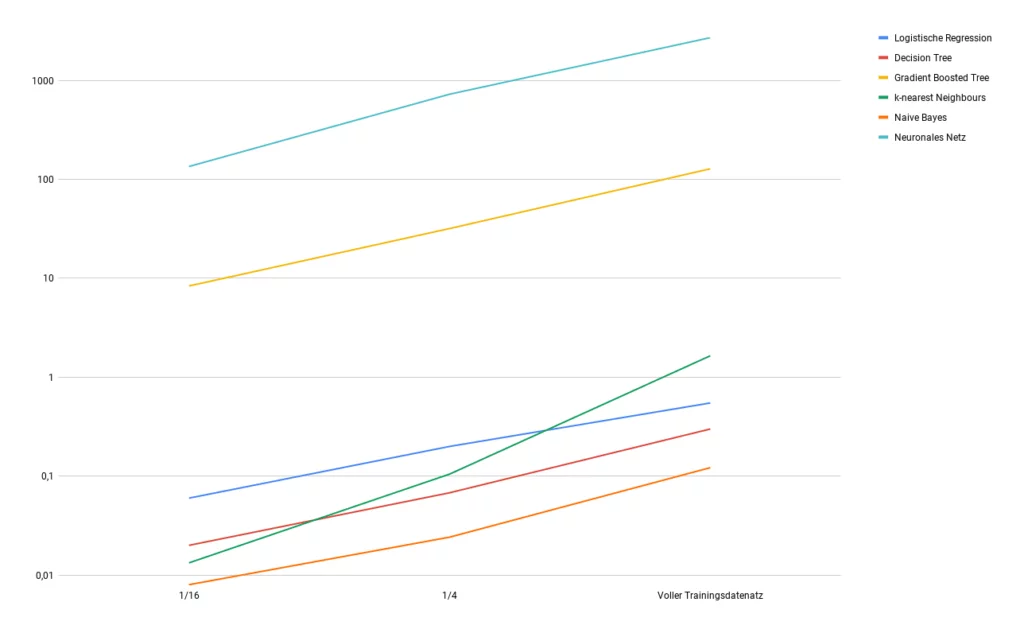
Zeit
Auch wenn die für das Training benötigte Zeit keine Aussage über die Qualität eines Klassifikators liefert, ist es häufig wichtig, zu berücksichtigen wie schnell ein Klassifikator trainiert werden kann. Die verschiedenen Verfahren sind unterschiedlich komplex was dazu führt, dass die Unterschiede der Zeit- und Rechenaufwände signifikant sein können.
Diese Zeitunterschiede können mit zunehmender Datensatzgröße exponentiell anwachsen, weshalb der Aspekt der Zeit, die ein Klassifikator bis zum Erreichen einer gewissen Genauigkeit benötigt, nicht zu vernachlässigen ist, besonders dann, wenn man mit sehr großen Datenmengen arbeitet. Um diesen Aspekt zu verdeutlichen, haben wir unsere Modelle auf reduzierten Datensätzen trainiert und die zeitlichen Unterschiede gemessen. Dabei haben wir folgendes Ergebnis erhalten.