
An artificial neural network is a mathematical model that is based on biological neural networks found in animal brains. Within such a network, groups of neurons are combined in multiple layers that are connected to each other.
Each neural network has at least one input layer and one output layer. In addition, any number of layers, known as hidden layers, can be placed in between the input and the output layer, as is the case in deep learning. In practice, more hidden layers in a network result in a higher degree of complexity and depth, but also more computing power required to train and run the model.
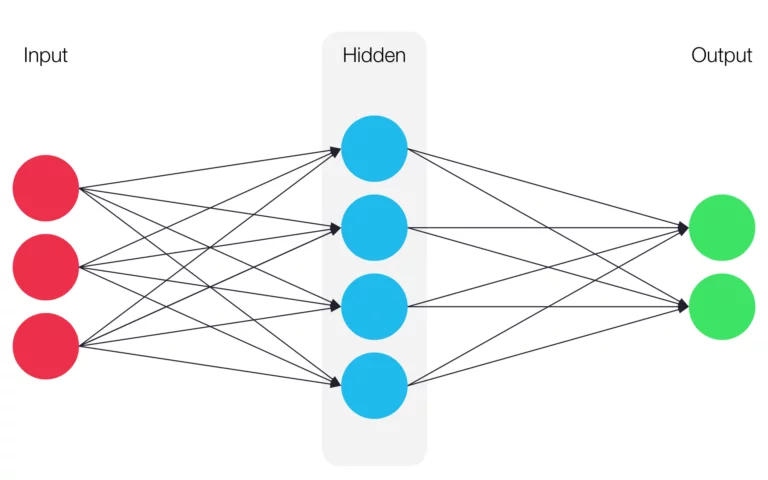
How Artificial Neural Networks Work
In a neural network, the neurons of adjacent layers are connected to each other using weighted connections. This weighting indicates the influence of the respectively connected neurons. When the network is initialized, the weights are initialized with random values.
Neurons of hidden layers will always have an input and an output. The total input of a neuron, known as the network input, specifies a propagation function such as the linear combination of values. The linear combination adds up the inputs multiplied by the respective weights.
Next, the activation function is used to calculate the activity of a neuron (or its activity level). In order for neural networks to be able to solve nonlinear problems, the activation function must be a nonlinear function such as the sigmoid function or the rectifier function and the corresponding rectified linear unit (ReLU), which has recently gained widespread popularity. The rectifier function has the form:
𝑓(𝑥) = max(0 , 𝑥)

The output functions of a neuron determines its output. The neuron transfers this output weight to the next neurons in the layer. Usually, the identity function is used for this, where the output is equal to the activity level (id(𝑥) = 𝑥).
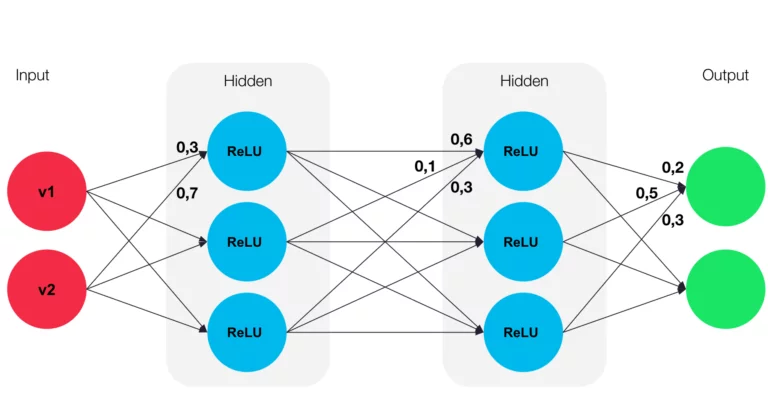
Sample Calculation
You have 2 input vectors v1 = 0,5 und v2 = 0,8. The propagation function as in the example of the graph would be calculated as:
0,3 * 0,5 + 0,8 * 0,7 = 0,71
With this value you can calculate the activation function, in this example calculating using the rectifier function:
f(𝑥) = max(0 , 0,71)
Afterwards the result is transferred to the output function:
id(0,71) = 0,71
Training Processes
According to certain learning rules, weight adjustment takes place with each training process. The weight of neuron connections are adjusted in such a ways that the output of the model is moved closer and closer to the desired result.
A frequently used learning rule when working with neural networks is called backpropagation.
Backpropagation
In backpropagation, an external “teacher” compares the result of the neural network with the desired outcome, determines the quadratic error, and then the information is fed back into the net. During this process, the weight in each layer is adjusted so that the resulting error becomes smaller and smaller over time. This is done using the gradient method; a numerical method for determining the minimum of a function. This method usually only finds a local minimum, however, it is still used in practice because it is too complex and costly to determine a global minimum arithmetically.
In order to use backpropagation, one needs a large amount of already labeled data to train the neural network. This is due to the fact that this method requires a relatively low learning rate. The low learning rate is necessary because the gradient method gradually approaches the minimum instead of taking big of steps and mistakenly skipping over the minimum. One of the advantages of backpropagation is that it can be applied to multi-layer networks.
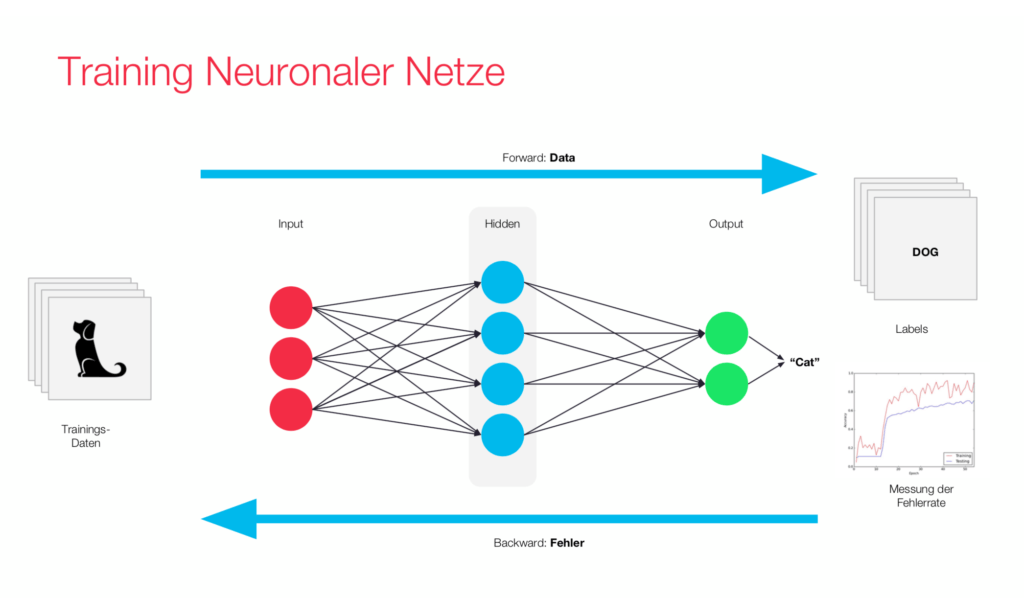
Test Phase
After the training has been completed, the net needs to be evaluated for whether or not it has learned something or if meaningful weight adjustments have taken place; this is called model validation. To do this, you give the model many learned inputs as well as unlearned inputs which makes it possible to examine if the model has just recorded or memorized the training objects or whether it actually solves general tasks correctly.
Network Types
Feed Forward Neural Network
A feed forward neural network is an artificial network in which information is passed layer by layer from the input to the output layer. It is important that the information is always transferred in the direction of the output layer and never the other way around.
There are also 2 types of feed forward neural networks:
Perceptron
The perceptron is the simplest form of an artificial neural network. First introduced in 1958 by Frank Rosenblatt, it has only one neuron, which is also the output vector. The input weights were already adjustable, allowing the perceptron to classify inputs that differ slightly from the vector originally learned. However, not only the original version of the perceptron is referred to as such, but instead, a distinction is made between the following variants:
- Single Layer Perceptron:
The single layer perceptron corresponds to the perceptron originally published by Rosenblatt as described above. - Multi Layer Perceptron (MLP):
The multi-layer Perceptron has several layers of neurons. In most cases, a sigmoid function is used as an activation function. An advantage of MLPs compared to simple perceptrons is that they are able to solve nonlinear problems.
Convolutional Neural Network (CNN)
The convolutional neural network usually has at least 5 layers and the main principle of CNNs is that each layer performs pattern recognition. With pattern recognition, each layer is refined further based on the output of the previous layer in a local region. This procedure is based on the receptive field that, for example, can be found on the retina of the human eye. Because backpropagation is used as the learning method, however, a large amount of labeled training data is necessary for CNNs to deliver useful results.
CNNs are used for image and video recognition, image classification and natural language processing, among other things, and have delivered outstanding results in recent years in competitions such as the SQuAD (Stanford Question Answering Dataset) test.
Recurrent Neural Networks
In contrast, to feed forward networks, recurrent neural networks allow information to go backward and pass through areas of the network again, which means that neurons can also return information to previous layers. This creates a kind of memory in the neural network. Recurrent neural networks are able to predict the future input of a range of inputs, which is why they are often used for handwriting or speech recognition.
The following types of Recurrent Neural Networks can be distinguished:
- Direct Feedback:
Neurons are fed their immediate output as an input - Indirect Feedback:
The output is fed back to the input of the neurons from previous layers - Lateral Feedback:
The output of a neuron is passed on to the input of a neuron of the same layer - Complete Connections:
All neurons are connected to each other


