
Unter einem künstlichen neuronalen Netz versteht man ein, an biologische neuronale Netze angelehntes, Rechenmodell. Innerhalb des Netzes werden Neuronengruppen in mehreren Layern zusammengefasst und miteinander verbunden.
Ein neuronales Netz besitzt immer mindestens einen Input-Layer und einen Output-Layer. Dazwischen befinden sich theoretisch beliebig viele sogenannte hidden- oder versteckte Layer. Man spricht von Deep Learning, wenn mehrere hidden Layer vorhanden sind. Je mehr hidden Layer ein Netz besitzt, desto höher ist dessen Grad an Komplexität, dessen tiefe und auch die benötigte Rechenleistung.
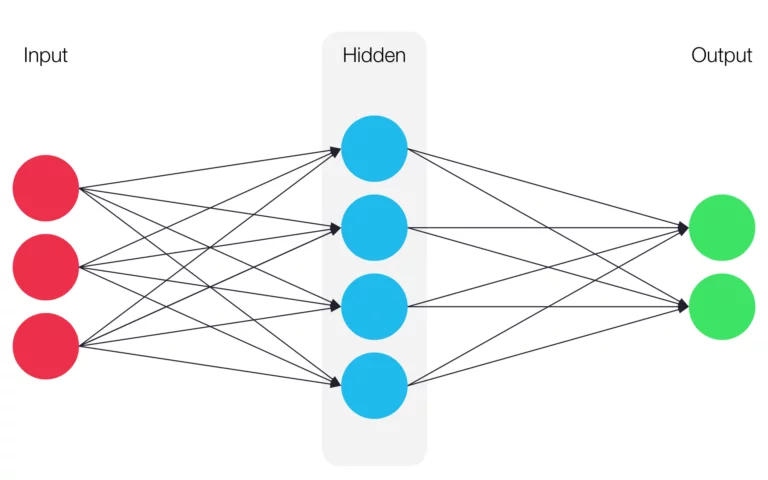
Funktion eines künstlichen neuronalen Netzwerks
Die Neuronen benachbarter Layer sind jeweils miteinander verbunden. Diese Verbindungen bekommen zunächst eine zufällige Gewichtung. Die Gewichtung gibt den Einfluss der jeweils verbundenen Neuronen an. Neuronen der hidden Layer haben immer einen Input und einen Output.
Der gesamte Input eines Neurons, Netzinput genannt, bestimmt eine sogenannte Propagierungsfunktion z.B. die Linearkombination. Die Linearkombination addiert die mit den jeweiligen Gewichten multiplizierten Inputs auf. Die einzige Ausnahme dazu bildet der Inputlayer.
Mit der sogennanten Aktivierungsfunktion berechnet man die Aktivität eines Neurons (bzw. sein Aktivitätslevel). Damit neuronale Netze nicht lineare Probleme lösen können, muss die Aktivierungsfunktion eine nicht lineare Funktion sein. Häufig wird als Aktivierungsfunktion die Sigmoid Funktion oder die, besonders in letzter Zeit an Popularität gewinnende, ReLU Funktion verwendet. Die ReLU Funktion hat die Form:
𝑓(𝑥) = max(0 , 𝑥)

Die sogenannte Ausgabefunktion eines Neurons bestimmt dessen Output. Diesen übergibt das Neuron gewichtet an die Neuronen des nächsten Layers. Häufig verwendet man dafür schlicht die Identitätsfunktion, bei der der Output dem Aktivitätslevel entspricht (id(𝑥) = 𝑥).
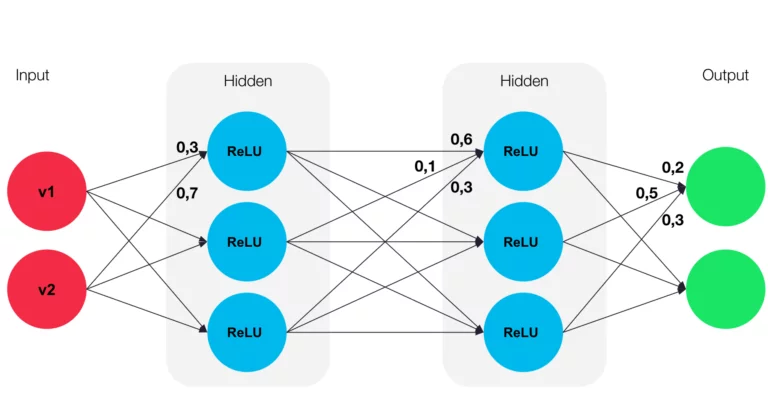
Rechenbeispiel
Man habe 2 Inputvektoren v1 = 0,5 und v2 = 0,8. Dann berechnet man die Porpagierungsfunktion wie am Beispiel der Grafik:
0,3 * 0,5 + 0,8 * 0,7 = 0,71
Mit diesem Wert kann man die Aktivierungsfunktion, in diesem Beispiel die ReLU Funktion, berechnen:
f(𝑥) = max(0 , 0,71)
Anschließend übergibt man nun noch das Ergebnis in die Ausgabefunktion:
id(0,71) = 0,71
Lernvorgang
Die Gewichtsanpassung geschieht bei jedem Lernvorgang anhand bestimmter Lernregeln. Diese passen die Gewichte der Verbindungen der Neuronen so an, dass sich der Output eines Modells dem gewünschtem Output immer weiter annähert.
Eine häufig verwendete Lernregel beim Einsatz von neuronalen Netzen ist die Backpropagation.
Backpropagation
Bei der Backpropagation vergleicht ein externer „Lehrer“ das Ergebnis des neuronalen Netzes mit dem gewünschten Ergebnis. Dabei bestimmt er den quadratischen Fehler. Dieser wird anschließend rückwärtig in das Netz gegeben. Dabei passt das Verfahren die Gewichte in jeder Schicht so an, dass der Fehler immer kleiner wird. Dies geschieht über das Gradientenverfahren. Das Gradientenverfahren ist ein numerisches Verfahren zur Bestimmung des Minimums einer Funktion. Diese Methode findet in der Regel nur ein lokales Minimum. Man setzte es ein, da es zu aufwendig ist ein globales Minimum arithmetisch zu bestimmen.
Um die Backpropagation anzuwenden benötigt man eine große Menge gelabelter Daten, um das neuronale Netz zu trainieren. Das ist darauf zurückzuführen, dass man bei dieser Methode eine relativ kleine Lernrate verwenden muss. Die kleine Lernrate ist deswegen notwendig, weil man sich mit dem Gradientenverfahren schrittweise dem Minimum annähert. Falls man zu große Schritte macht, kann es sein, dass man das Minimum überspringt. Der Vorteil, den die Backpropagation bringt, ist, dass man sie auf mehrschichtige Netze anwenden kann.
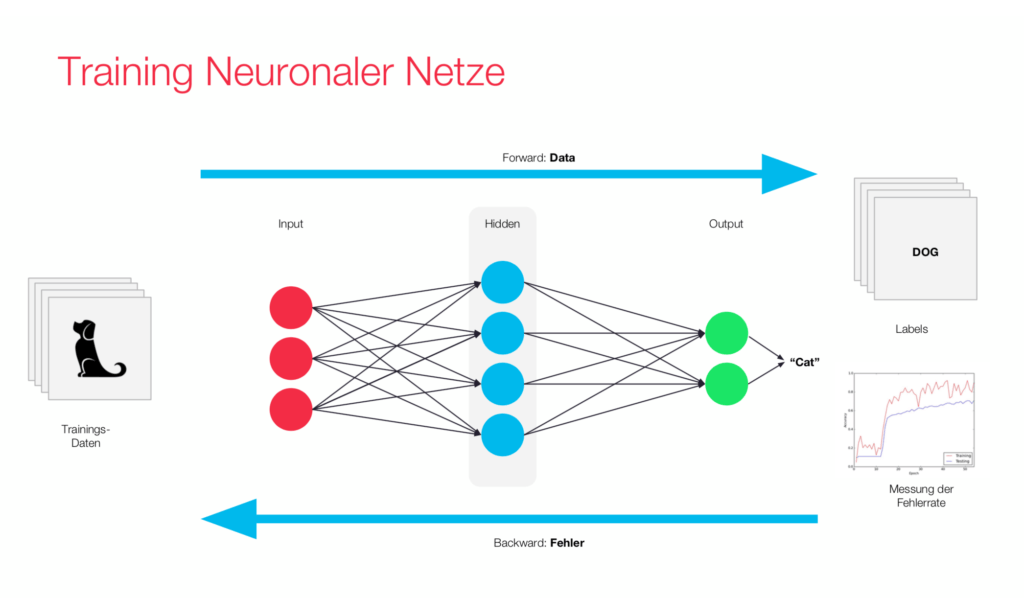
Testphase
Nachdem das Training abgeschlossen ist, wird überprüft, ob das Netz etwas gelernt hat, sprich ob sinnvolle Gewichtsanpassungen stattgefunden haben. Man spricht von der Modellvalidierung. Dafür verwendet man die Menge der erlernten Inputs, wie auch eine Menge von nicht erlernten Inputs. Damit ist es möglich zu untersuchen, ob das Modell einerseits die Trainingsobjekte erfasst hat und andererseits, ob es allgemeine Aufgaben richtig löst.
Netztypen Überblick
Feedforward Neural Network
Ein Feedforward Neural Network ist ein künstliches neuronales Netzwerk, bei dem die Informationen schichtweise von dem Input zum Outputlayer weiter gegeben werden. Wichtig hierbei ist, dass die Informationen stets in Richtung Outputlayer und nie in Richtung des Inputlayers übergegeben werden.
Weiter kann man 2 Arten der Feedforward Neural Networks unterscheiden:
Perceptron
Das Perceptron ist die einfachste Form eines künstlichen neuronalen Netzes. Erstmals 1958 von Frank Rosenblatt vorgestellt, besitzt es lediglich ein Neuron, welches zugleich der Ausgabevektor ist. Die Inputgewichte waren bereits anpassbar, wodurch das Perceptron in der Lage ist, Inputs, die leicht vom ursprünglich gelernten Vektor abweichen, zu klassifizieren. Allerdings wird nicht nur die ursprüngliche Version des Perceptrons als solches bezeichnet, stattdessen wird zwischen folgenden Varianten unterschieden:
- Single-layer Perceptron:
Das Single-layer Perceptron entspricht dem ursprünglich von Rosenblatt veröffentlichten Perceptron. - Multi-layer Perceptron (MLP):
Das Multi-layer Perceptron besitzt mehere Layer von Neuronen. In den meisten Fällen wird eine Sigmoid Funktion als Aktivierungsfunktion verwendet. Ein Vorteil der MLPs im Vergleich zu einfachen Perceptrons besteht darin, dass sie in der Lage sind nicht lineare Probleme zu lösen.
Convolutional Neural Network (CNN)
Das Convolutional Neural Network besitzt in der Regel mindestens 5 Layern. Das Prinzip der CNNs besteht darin, dass jeder Layer eine Mustererkennung durchführt. Dabei wird die Mustererkennung mit jedem Layer auf Basis des Outputs des vorherigen Layers in einer lokalen Region weiter präzisiert und abstrahiert. Dieses Verfahren ist an das rezeptive Feld, dass zum Beispiel auf der Netzhaut des menschlischen Auges zu finden ist, angelehnt. Damit CNNs brauchbare Ergebnisse liefern, ist eine große Menge an gelabelten Trainingsdaten notwendig, da als Lernmethode die Backpropagation verwendet wird.
CNNs werden unter Anderem für die Bild- und Videoerkennung, sowie die Bildklassifizierung und natürliche Sprachverarbeitung eingesetzt und konnten in den letzten Jahren bei Wettbewerben, wie dem SQuAD (Stanford Question Answering Dataset) Test herausragende Ergebnisse liefern.
Recurrent Neural Networks
Recurrent Neural Networks erlauben im Gegensatz zu Feed Forward Networks, dass Informationen Bereiche des Netzes erneut durchlaufen können, das heißt Neuronen können Informationen auch an vorherige Layer zurückgeben. Dadurch entsteht eine Art Gedächtnis im neuronalen Netz. Recurrent Neural Networks sind in der Lage, Vorhersagen über den zukünftigen Input einer Reihe von Inputs zu treffen, weshalb sie häufig für die Handschrift- oder Spracherkennung eingesetzt werden.
Folgende Arten Recurrent Neural Networks lassen sich unterscheiden:
- Direct Feedback:
Neuronen erhalten als Input ihren zurückgeführten Output - Indirect Feedback:
der Output wird an den Input der Neuronen aus vorherigen Schichten zurückgeführt - Lateral Feedback:
der Output eines Neurons wird an den Input eines Neurons des selben Layers weitergeleitet - Vollständigen Verbindungen:
alle Neuronen sind miteinander Verbunden


