Das Verfahren der Modellvalidierung beschreibt die Methode, ein statistisches oder datenanalytisches Modell auf Performance zu überprüfen.
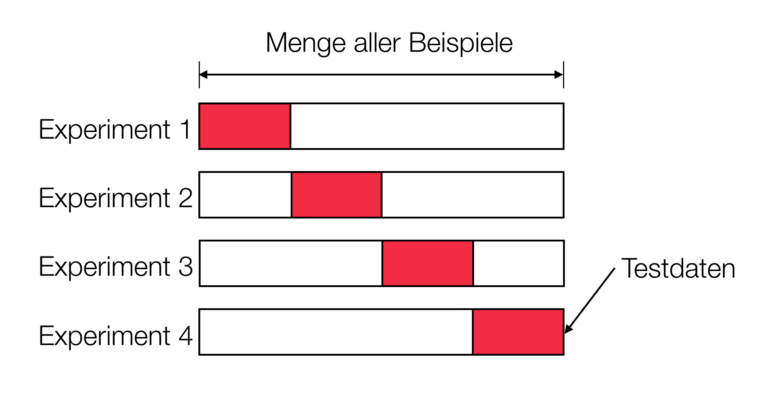
Ein verbreitetes Verfahren zur Validierung von neuronalen Netzen ist die k-fold Cross Validation. Dabei teilt man Trainingsdatensatz in k Teilmengen auf. Dabei stellt eine der Teilmengen die Testmenge dar. Die restlichen Teilmengen dienen dann als Trainingsmenge. Die Trainingsmenge dient dabei zum Training des Modells. Durch das Verhältnis der richtigen Ergebnisse auf der Testmenge ist es möglich den Grad der Generalisierung des Modells zu bestimmen. Anschließend vertauscht man die Testmenge mit einer Trainingsmenge und bestimmt die Performance erneut, bis schließlich jede Menge als Testmenge fungiert hat. Am Ende des Vorgangs berechnet man nun den durchschnittlichen Grad der Generalisierung zur Abschätzung der Performance des Modells. Der Vorteil dieses Verfahrens ist, dass man eine relativ varianzfreie Performanceeinschätzung erhält. Grund dafür ist, dass verhindert möglichst verhindern wird, wichtige Strukturen in den Trainingsdaten auszuschließen.
Dieses Verfahren ist im Grunde eine Erweiterung der Holdout Methode. Die Holdout Methode teilt den Datensatz allerdings schlicht in eine Trainings- und in eine Testmenge auf. Gefahr bei dieser Methode ist im Gegensatz zur k-fold Cross Validation, dass wichtige Daten nicht zum Training zur Verfügung stehen könnten. Dies kann dazu führen, dass das Modell nicht ausreichend in der Lage zu generalisieren ist.
Overfitting
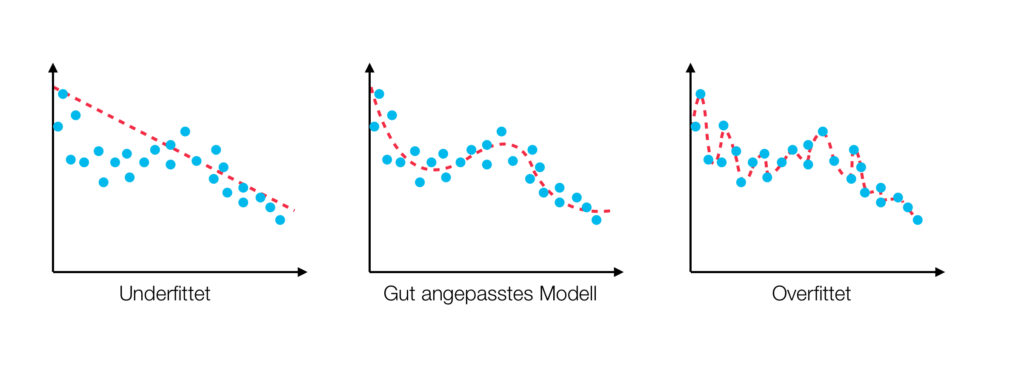
Von Overfitting (deutsch: „Überanpassung“) spricht man, wenn ein Modell zu speziell an einen Trainingssatz angepasst ist. Bei neuronalen Netzen zum Beispiel, würde das bedeuten, dass ein Netz für Inputs aus dem Trainingsdatensatz sehr genau ist, für einen Testsatz allerdings nicht. Daraus folgt zwar, dass das Modell die trainierten Daten sehr genau abbilden kann, es aber nicht in der Lage ist, generalisierte Ergebnisse zu erzielen.
In der Regel tritt Overfitting dann auf, wenn der Trainingsdatensatz relativ klein und das Modell relativ komplex ist. Denn ein komplexes Modell kann die Trainingsdaten genauer abbilden, umgekehrt bildet ein simples Modell die Trainingsdaten nicht so genau ab (Underfitting). Also ist es allgemein sinnvoll, je nach dem vorhandenen Datensatz, das Modell so simpel wie möglich und gleichzeitig nicht zu simpel zu halten. Ein perfektes Modell, das heißt ein Modell, bei dem es weder zu Over, noch zu Underfitting kommt ist nahe zu unmöglich zu erstellen.
Um das Problem des Overfitting zu reduzieren und gleichzeitig das Underfitting gering zu halten, wurden mehrere Verfahren eingführt. So unter anderem das von Google patentierte Dropout. Das Prinzip des Dropout ist recht simpel. Es deaktiviert lediglich eine gewisse Anzahl, in der Regel zwischen 20% und 50%, je nach festgelegtem Faktor, der Neuronen zufällig. Diese Methode erreicht trotz ihrer Einfachheit eine signifikante Reduzierung von Overfitting.