
Dies ist der zweite Teil unserer Serie Automatisierte Klassifizierung in Python, bei der wir verschiedene Verfahren anwenden, um den UCI Machine Learning Datensatz “UCI Machine Learning record “Adult”” zu klassifizieren. Nachfolgend gehen wir näher darauf ein, wie wir, nach der Vorbereitung unserer Daten im 1. Teil, die verschiedenen Modelle implementieren und anschließend auf ihre Performance vergleichen.
Klassifizierung
Wir verwenden für die Klassifizierung verschiedene scikit-learn Modelle. Die scikit-learn Bibliothek ist open-source und stellt eine Vielzahl an Tools zur Datenanalyse bereit. Unser Ziel ist es die Performance der folgenden Modelle miteinander zu vergleichen: logistische Regression, Decision Trees, Gradient Boosted Trees, k-Nearest Neighbors, Naive Bayes und ein neuronales Netz. Weiter unten fassen wir die genutzten Verfahren noch einmal kurz zusammen.
Im Allgemeinen verwenden die Modelle den Trainingsdatensatz, um eine Funktion zu erstellen, die die Beziehung zwischen Features und Targets beschreibt. Diese Funktion können wir nach dem Training auf Daten außerhalb des Trainingsdatensatzes anwenden, um deren Targets vorherzusagen. Weitere Informationen dazu, wie diese Funktion entsteht, haben wir in unserem Blog zusammengefasst. In unserem Fall übernimmt die scikit-learn Methode “fit” das Training der Modelle. Nachfolgend zeigen wir unsere Implementierung eines Modells anhand des folgenden Codebeispiels:
def do_decision_tree(self):
""" Return a decision tree classifier object. """
clf = tree.DecisionTreeClassifier()
return clf.fit(self.x_train, self.y_train)Code-Sprache: PHP (php)Wir erzeugen ein scikit-learn Decision Tree Classifier Objekt und trainieren es anschließend auf unserem Trainingsdatensatz.
Mit der scikit-learn Methode “predict” ist es möglich, ein Modell für einzelne Daten oder einen gesamten Datensatz Targets bestimmen zu lassen. Anhand der gewonnenen Ergebnissen bestimmen wir die Performance des Modells.
Klassifizierungsmodelle
In diesem Abschnitt fassen wir die Funktionsweise der einzelnen Verfahren kurz zusammen. Für eine genauere Erklärung des Modells, haben wir jeweils den passenden Beitrag aus unserem Blog und der scikit-learn Dokumentation verlinkt.
Logistische Regression
Die logistische Regression transformiert eine lineare Regression zu einer Sigmoidfunktion. Dadurch gibt die logistische Regression stets Werte zwischen 0 und 1 aus. Im Allgemeinen werden dabei jeweils Koeffizienten der einzelnen unabhängigen Features so angepasst, dass sich die einzelnen Objekte möglichst genau ihren Targets zuordnen lassen.
Decision Tree
Decision Tree Modelle sind einfache Entscheidungsbäume in der jeder Knoten ein Attribut abfragt, wonach der nächste Knoten wieder ein Attribut abfragt. Dies geschieht so lange, bis ein Blatt erreicht wird, dass den jeweiligen Klassifizierungsfall angibt. Weitere Informationen zu Decision Trees findest du in unserem Artikel zum Thema Klassifizierung.
Gradient Boosted Trees
Gradient Boosted Trees sind Modelle die aus mehreren einzelnen Decision Trees bestehen. Ziel ist es aus vielen simplen Modellen ein komplexes Modell zu entwerfen. Dabei wird nach einer differenzierbaren Verlustfunktion optimiert, indem die Koeffizienten der einzelnen Bäume so angepasst werden, dass die Verlustfunktion möglichst klein wird.
k-nearest Neighbors
Bei dem k-nearest Neighbors Modell werden die einzelnen Objekte in einem Vektorraum betrachtet und in Abhängigkeit zu den k nächsten Nachbarn klassifiziert. Eine ausführliche Erklärung zu diesem Modell ist in unserem Artikel zum Thema Klassifizierung zu finden.
Naive Bayes
Das Native Bayes Modell betrachtet Objekte als Vektoren, deren Einträge jeweils einem Feature entsprechen. Dabei wird die Wahrscheinlichkeit der Zugehörigkeit jedes einzelnen Eintrags zum Target bestimmt und anschließend aufsummiert. Das Objekt wird dabei dem Target zugeordnet, dessen summierte Wahrscheinlichkeit am höchsten ist. Weitere Informationen zu dem Naive Bayes Modell sind in ebenfalls in unserem Artikel zum Thema Klassifizierung zu finden.
Neural network
Neuronale Netze bestehen aus einer oder mehreren Schichten von einzelnen Neuronen. Beim Training eines Neuronalen Netzes werden die gewichteten Verbindungen so angepasst, dass eine Verlustfunktion minimiert wird. Wir haben viele weitere Informationen zum Aufbau und der Funktion von neuronalen Netzen in unserem Artikel „Was sind künstliche neuronale Netze?“ zusammengefasst.
Performance Determination
Für die Bestimmung der Performance unserer Modelle haben wir eine Funktion “get_classification_report” geschrieben. Diese gibt uns die Metriken Precision, Recall, F-Score und die Fläche unter der ROC Kurve, sowie die dafür benötigten Kennzahlen, die wir jeweils in unserem Artikel näher beschreiben, durch den Aufruf der scikit-learn Funktion “metrics.classification_report” und “metrics.confusion_matrix” aus.
def get_classification_report(self, clf, x, y, label=""):
""" Return a ClassificationReport object.
Arguments:
clf: The classifier to be reported.
x: The feature values.
y: The target values to validate the predictions.
label: (optionally) sets a label."""
roc_auc = roc_auc_score(y, clf.predict_proba(x)[:,1])
fpr, tpr, thresholds = roc_curve(y, clf.predict_proba(x)[:,1])
return ClassificationReport(metrics.confusion_matrix(y, clf.predict(x)),
metrics.classification_report(y, clf.predict(x)), roc_auc, fpr, tpr, thresholds , label)Code-Sprache: PHP (php)Lediglich die Receiver Operating Characteristic erhalten wir in Form eines Graphen der mit Hilfe der Python Bibliothek matplotlib und der scikit-learn Funktionen “roc_auc_score” und “roc_curve” erzeugt wird.
Auswertung
Finally, we discuss how the models have performed on our data.
| Klassifikator | Precision | Recall | F-Score | Area under Curve | Trainingszeit (Sekunden) |
| Logistische Regression | 83% | 84% | 83% | 87% | 0,8 |
| Decision Tree | 82% | 82% | 82% | 77% | 0,5 |
| Gradient Boosted Trees | 88% | 88% | 87% | 93% | 142,9 (2 Minuten) |
| k-nearest Neighbors | 84% | 84% | 84% | 88% | 2,1 |
| Naive Bayes | 84% | 83% | 83% | 89% | 0,1 |
| Neuronal Networks | 83% | 83% | 83% | 89% | 1.746 (29 Minuten) |
A direct comparison shows that neural networks need very long training times in order to achieve adequate results. With our settings, the training lasted about 29 minutes and a precision of 83% was achieved. In contrast, the Naive Bayes classifier achieved the same accuracy in just one-tenth of a second.
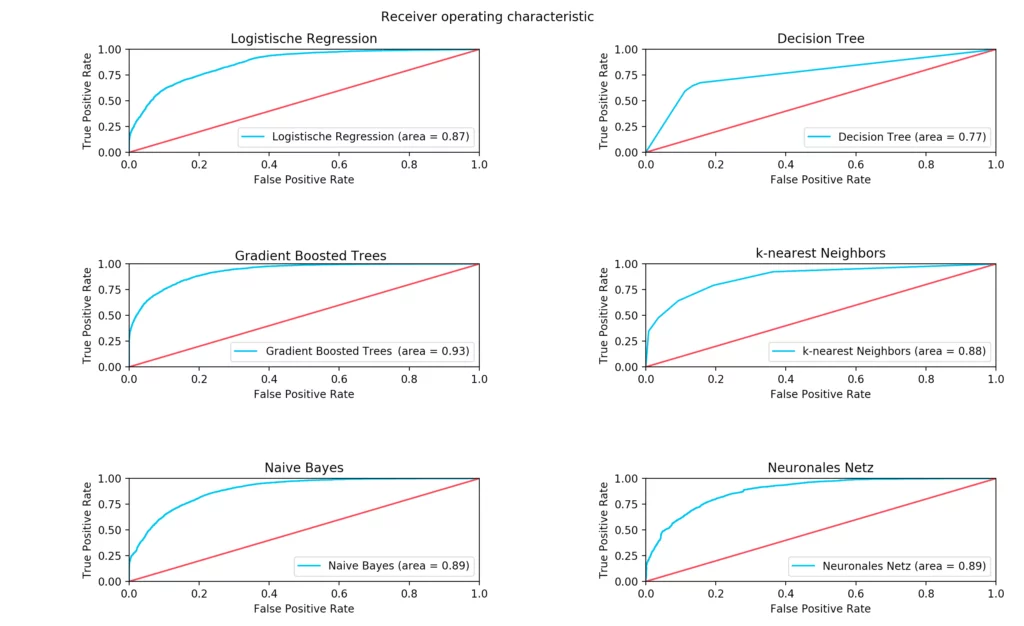
The best result was achieved with the Gradient Boosted Trees. This classifier managed to achieve a precision of 88% in 143 seconds. In addition to the relatively poor result of the neuronal net for the required training duration, it must be said that our model was most likely not chosen optimally.
In addition, the training of the neural net and the gradient boosted trees weren’t done on GPUs, which would have reduced the training duration.


