
Machine Learning ermöglicht Computern Wissen aus Daten zu erlernen, ohne dieses explizit zu programmieren. Dieses Wissen stellt eine Funktion dar, die einem Input einen passenden Output zuordnet. Ein Algorithmus passt die Funktion dabei so lange an, bis sie die gewünschten Ergebnisse erzielt. Man spricht vom Training des Modells. In den letzten Jahren haben sich eine Reihe von Trainingsverfahren etabliert, die erst mit der Verfügbarkeit von sehr großen Datensätzen zu guten Ergebnissen führen. Die Formulierung „Daten sind das neue Öl“ bezieht sich häufig auf die Tatsache, dass Unternehmen mit reicheren Datensätzen mächtigere Modelle trainieren können.
Narrow AI vs. General AI
Unsere heutigen Machine Learning Algorithmen sind grundsätzlich nur auf sehr spezifische Probleme anwendbar. Man spricht von einer sogenannten Narrow AI. Im Gegensatz dazu steht die sogenannte General AI. Unter einer General AI versteht man einen Algorithmus, der ein abstraktes Weltbildmodell erlernt. Dieser wäre in der Lage, ähnlich wie ein Mensch, Wissen aus verschiedenen Bereichen zu kombinieren und dieses auf bisher unbekannte Probleme zu übertragen. Von einer solchen General AI sind wir jedoch noch entfernt. Es ist nicht einmal geklärt, ob eine solche General AI grundsätzlich möglich ist. Dennoch: Narrow AI ist heute schon in der Lage, Probleme, die früher schwer oder gar nicht durch Computer zu lösen waren, effizienter als Menschen zu lösen.

Supervised und Unsupervised Learning
Es existieren zwei Ansätze Machine Learning Modelle zu trainieren. Einerseits gibt es das Supervised Learning und andererseits das Unsupervised Learning. Bei Supervised Learning sind zur Trainingszeit der Input und der dazu gewünschte Output bekannt. Der Algorithmus erzeugt aus diesen Informationen ein Modell, das die Beziehung von Input zu Output beschreibt. Dieses Modell kann nach dem Training allgemeine, das heißt nicht auf den Traningsdatensatz beschränkte, Ergebnisse zu einem Input liefern. So verwendet man Supervised Learning Training für das Erkennen von Bildinhalten. Beim Training werden Bilder mit einer Liste von Bildinhalten für jedes Bild als Input geliefert. Durch das Training soll das Modell als Output die richtigen Objekte erkennen können.
In Unsupervised Learning, however, the program does not receive any information about the desired output. The program then has to create a model that generates suitable outputs for given inputs on the basis of their similarities. It is difficult to judge the result of such a model qualitatively because there is no specification for the results. The automatic recognition of clusters in quantitative data is a typical problem, however, unsupervised learning models achieve good results. Among other things, a program can automatically recognize outliers and new patterns in data.
Problemstellungen die Machine Learning lösen kann
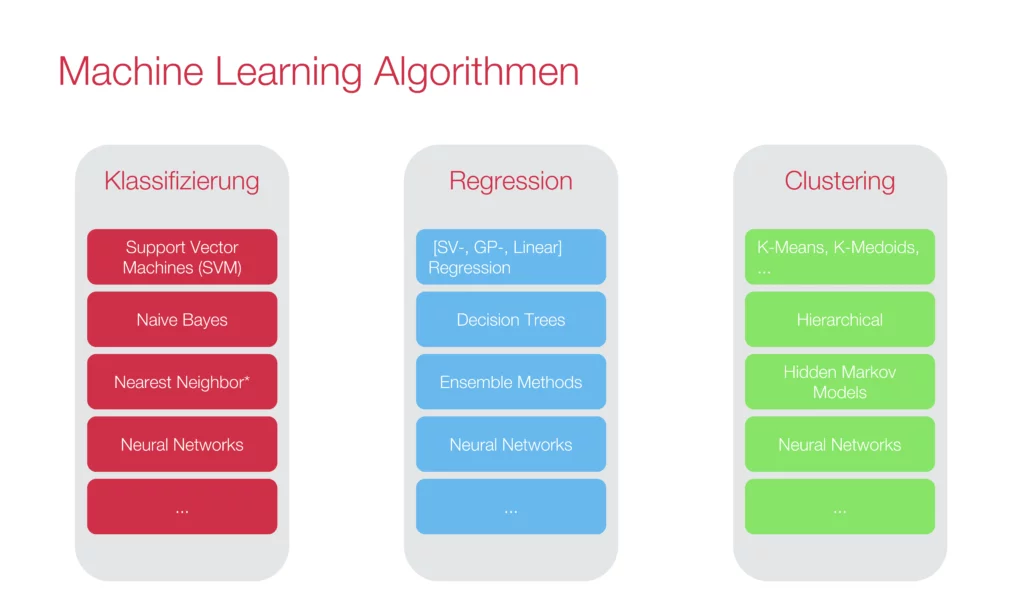
Wie bereits erwähnt, werden Machine Learning Algorithmen aktuell auf sehr spezifische Probleme angewendet. Es können drei abstrakte Problemtypen gelöst werden:
Das Klassifizierungsproblem
Unter dem Klassifizierungsproblem versteht man das automatisierte Zusammenfassen von Objekten zu Klassen. Ein klassisches Beispiel hierfür ist ein Programm, das in der Lage ist zu erkennen, ob sich auf einem Bild eine Katze oder ein Hund befindet. Für Klassifizierungsprobleme finden Supervised Learning Modelle häufig Verwendung. Anhand von geeigneten Beispielen erlernt das Modell selbstständig, Objekte den richtigen Klasse zuzuordnen. Welche Eigenschaften dabei betrachtet werden, wird dem Modell je nach Verfahren vorgegeben (Feature Engineering), oder ebenfalls automatisiert erlernt.
Das Regressionsproblem
Bei dem Regressionsproblem geht es darum, den zukünftigen Verlauf einer Funktion abzuschätzen. Ein klassisches Beispiel hierfür wäre die Vorhersage des Pegelstands eines Flusses. Hierbei werden Rückschlüsse aus den Vorjahren gezogen, um den zukünftigen Stand vorherzusehen. Oft kommt hierfür ein Supervised Learning Modell zum Einsatz. Dieses lässt sich mit historischen Daten trainieren, welche Schlüsse auf zukünftige Daten zulassen
Das Clusteringproblem
Die Zielstellung beim Clusteringproblem ist es, einen Algorithmus zu entwerfen, der selbstständig gegebene Daten in Gruppen ähnlicher Objekte kategorisiert. Häufig wird dazu ein Unsupervised Learning Modell verwendet. Ein solches Modell braucht keine genaueren Vorgaben, wonach es kategorisieren soll. Dadurch kann man sicherstellen, dass man gewisse Gruppen von Daten, die man selber als Entwickler womöglich gar nicht als solche wahrnimmt, nicht von vorne herein ausschließt. Ein klassisches Beispiel wäre die Zielgruppenanalyse im Marketing, wie die personenbezogene Werbung. Dabei werden Kunden in verschiedene Gruppen eingeteilt, um ihnen spezifische Werbung anzuzeigen.
Herausforderungen beim Einsatz von Machine Learning Verfahren
Beim Einsatz von Machine Learning Verfahren ergeben sich aber trotz der Menge an Vorteilen einige Herausforderungen wie:
Datenqualität
In der Praxis besteht ein Großteil der Arbeit von Machine Learning Projekten darin, die richtigen Daten zu beschaffen, zu verstehen und aufzubereiten. Dieser, im Allgemeinen „Preprocessing“ genannte, Schritt stellt sicher, dass die Daten genau repräsentieren, worauf das Modell auch tatsächlich trainiert werden soll. Besonders in größeren Organisationen ist bereits die Beschaffung und Aggregation der Daten keine triviale Aufgabe, bei der mehrere Abteilungen miteinander Kooperieren müssen. Stehen die nötigen Daten nicht um gewünschten Umfang oder der nötigen Qualität zur Verfügung, besteht die erste Projektphase häufig daraus, diese Daten zu sammeln und aufzubereiten.
Fehler und Verzerrungen in den Daten können dazu führen, dass das trainierte Modell diese ebenfalls erlernt, man spricht hier von „Biases“, also Vorurteilen, die sich aus den Daten abzeichnen.
Unterschiede zwischen verschiedenen Machine Learning Verfahren in Bezug zu Performance und Erklärbarkeit
Die verschiedenen Machine Learning Verfahren unterscheiden sich in Bezug zu ihrer Performance und ihrer jeweiligen Erklärbarkeit. Allgemein gilt, dass wenn ein Machine Learning Modell eine hohe Performance erzielt, seine Erklärbarkeit sinkt, wie auch umgekehrt.
Beispielsweise erzielen neuronale Netze eine sehr gute Performance, aber versucht man den Lösungsweg nachzuvollziehen, erkennt man, dass dieser nicht viel mit dem zu tun hat, was wir als logische Problemlösung verstehen würden. Das liegt daran, dass die Modelle aus zum Teil hunderten, oder gar mehr unabhängigen Variablen und noch viel mehr Berechnungen bestehen. Man spricht vom Black Box Problem. Problematisch wird diese Eigenschaft immer dann, wenn diese Informationen wichtig sind, z.B. bei lebenswichtigen Entscheidungen wie in der Medizin, wenn ein Machine Learning Modell eine Behandlung vorschlägt.
Im Gegensatz dazu gibt es Verfahren, wie die lineare Regression oder Decision Trees, die sehr evident sind. Das führt dazu, dass die Ergebnisse dieser Modelle zwar recht leicht erklärbar, die Modelle aber nicht gut für komplexe Probleme anwendbar sind.

Overfitting
Man spricht von Overfitting, wenn ein Machine Learning Modell nach dem Training nicht mehr in der Lage ist, allgemeine Ergebnisse zu erzielen. Das passiert, wenn man ein Machine Learning Modell zu häufig auf einem zu kleinen Trainingssatz trainiert. Die Fehlerquote bei diesem wird zwar immer kleiner, die Performance aber nicht unbedingt besser. Denn anstatt, dass das Modell eine allgemeine Funktion erzeugt, wirkt es eher als hätte es die Daten auswendig gelernt. Schließend werden korrekte Ergebnisse nur noch auf dem Trainigssatz erreicht.


