
Machine Learning enables computers to learn knowledge from data without someone or something explicitly programming it. This knowledge is a function that assigns a suitable output to an input. An algorithm adjusts the function until it achieves the desired results. In recent years, a number of training methods have been established, which only lead to good results with the availability of very large data sets. The phrase “data is the new oil” often refers to the fact that companies with richer data sets can train more powerful models.
Narrow AI vs. General AI
Our current machine learning algorithms are generally only applicable to very specific problems; a so-called, Narrow AI. General AI is an algorithm that learns an abstract world view model. Like a human being, this would be able to combine knowledge from different fields and transfer it to previously unknown problems. However, we are still a long way from such a General AI. It is not even clear whether such a General AI is possible in principle. Nevertheless: Narrow AI today is already able to solve problems that were previously difficult or impossible to solve with computers more efficiently than humans.

Supervised and Unsupervised Learning
There are two approaches to train Machine Learning models; supervised and unsupervised learning. In Supervised Learning, the input and the desired output are known at training time. From this information, the algorithm generates a model that describes the relationship between input and output. After the training, this model can provide general results for an input, i.e. results that are not limited to the training data set. For example, Supervised Learning Training is used to recognize image content. During training, images are provided with a list of image content for each image as input. The training should enable the model to recognize the correct objects as output.
In Unsupervised Learning, however, the program does not receive any information about the desired output. The program then has to create a model that generates suitable outputs for given inputs on the basis of their similarities. It is difficult to judge the result of such a model qualitatively because there is no specification for the results. The automatic recognition of clusters in quantitative data is a typical problem, however, unsupervised learning models achieve good results. Among other things, a program can automatically recognize outliers and new patterns in data.
Problems Machine Learning Can Solve
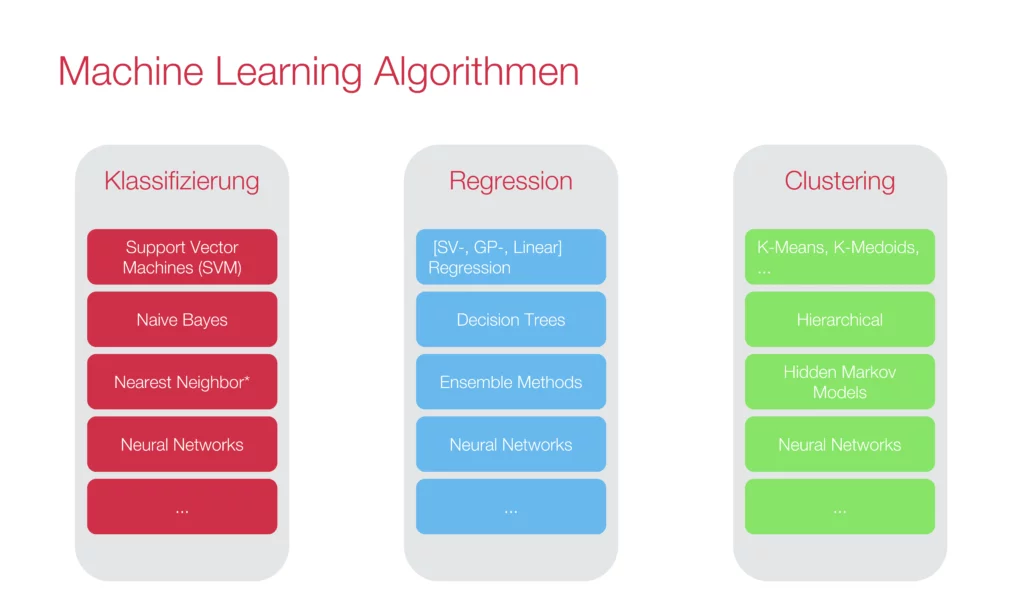
As mentioned earlier, machine learning algorithms are currently being applied to very specific problems. Three abstract problem types can be solved:
The Classification Problem
The classification problem is the automated grouping of objects into classes. A classic example of this is a program that is able to recognize whether a cat or a dog is on a picture. For classification problems, supervised learning models are often used. On the basis of suitable examples, the model independently learns to assign objects to the correct class. Which properties are considered is either given to the model depending on the method (Feature Engineering) or also learned automatically.
The Regression Problem
The Regression Problem is about estimating the future course of a function. A classic example would be the prediction of the water level of a river. Here, conclusions are drawn from previous years to predict the future situation. A supervised learning model is often used for this purpose. This model can be trained with historical data that allow conclusions to be drawn about future data.
The Clustering Problem
The goal of the clustering problem is to design an algorithm that independently categorizes given data into groups of similar objects; often an unsupervised learning model is used. Such a model does not need more precise specifications as to how it should categorize. This ensures that certain groups of data, which the developer may not even perceive as such, are not excluded from the outset. A classic example would be target group analysis in marketing, such as personal advertising. Customers are divided into different groups in order to display specific advertising.
Challenges when using Machine Learning Methods
However, the use of machine learning methods poses a number of challenges despite the many advantages:
Data Quality
In practice, much of the work of machine learning projects consists of obtaining, understanding, and preparing the right data. This step, generally called “preprocessing”, ensures that the data represents exactly what the model is actually trained on. Particularly in larger organizations, the collection and aggregation of data is not a trivial task where several departments have to cooperate with each other. If the necessary data is not available for the desired scope or quality, the first project phase often consists of collecting and processing this data.
Errors and distortions in the data can lead to the trained model also learning these, one speaks here of “biases”, i.e. prejudices that emerge from the data.
Differences Between Different Machine Learning Methods in terms of Performance and Explainability
The different machine learning methods differ in terms of their performance and their respective explanations. In general, if a machine learning model achieves high performance, its explainability decreases, as well as vice versa.
For example, neural networks perform very well but trying to understand the solution reveals that it does not have much to do with what we would understand as logical problem-solving. This is because the models consist of hundreds or even more independent variables and many more calculations. This is called the black box problem. This characteristic becomes problematic whenever this information is important, e.g. in vital decisions such as in medicine, when a machine learning model suggests a treatment.
In contrast, there are procedures such as linear regression or decision trees that are very evident. As a result, the models are not well suited for complex problems.

Overfitting
Overfitting occurs when a machine learning model is no longer able to achieve general results after training. This happens when you train a machine learning model too often on a training set that is too small. The error rate is getting smaller, but the performance is not necessarily better. Because instead of making the model a generic function, it seems more like it has memorized the data. Finally, correct results are only achieved on the training set.


