
Klassifizierungsverfahren teilen Objekte nach ihren Merkmalen mit Hilfe eines Klassifikators in vordefinierte Kategorien ein. Ein Klassifikator ist eine Funktion, die einen Input auf eine Klasse abbildet. Das Ziel besteht darin passende Regeln zu finden, wonach sich die Daten in die jeweiligen Klassen zuordnen lassen. Normalerweise geschieht dies im Machine Learning durch einen Supervised Learning Ansatz. In diesem Artikel stellen wir die gängigsten Machine Learning Verfahren zur Lösung von Klassifizierungsproblemen kurz vor.
Decision Trees
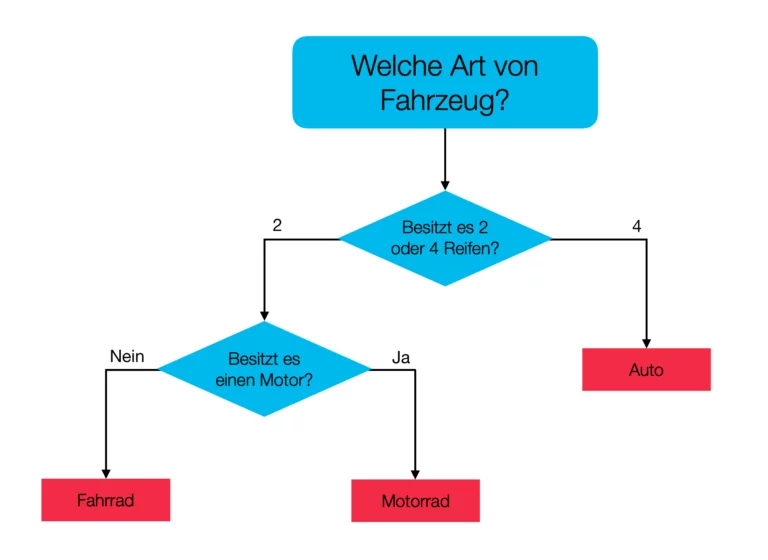
Decission Trees sind in ihrer einfachsten Form schlichte Entscheidungsbäume. Bei diesen geht man vom Wurzelknoten aus abwärts. Jeder Knoten fragt dabei ein Attribut ab. Anhand dieser Abfrage fällt die Entscheidung über den nachfolgenden Knoten, bis schließlich ein Blatt erreicht wird. Das erreichte Blatt ergibt den Klassifizierungsfall. Aus der Zusammensetzung mehrerer Decision Trees sind komplizierte Modelle wie die Boosted Trees, Gradient Boosting oder Random Forest entstanden.
Bayes-Klassifikation
Der Bayes-Klassifikator ordnet Objekte der Klasse zu, zu der sie am wahrscheinlichsten gehört. Grundlage für die Berechnung der Wahrscheinlichkeit ist dabei eine Kostenfunktion. Diese stellt die Objekte als Vektoren dar, bei denen jede Eigenschaft auf eine Dimension abgebildet wird. Dabei ermittelt die Kostenfunktion die Wahrscheinlichkeit, dass eine einzelne Eigenschaft des Objekts zu einer Klasse gehört. Die einzelnen Eigenschaften werden dabei unabhängig voneinander betrachtet. Zuletzt wird das Objekt der Klasse zugeordnet, deren einzelnen Wahrscheinlichkeiten am ehesten einer Klasse entsprechen.
k-Nearest-Neighbors
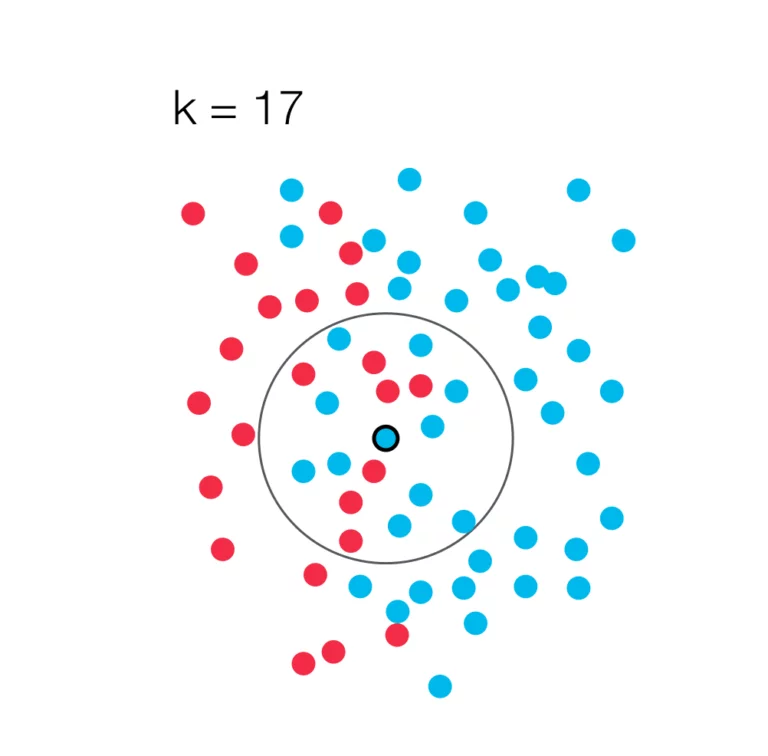
Die k-Nearest-Neighbors Methode bestimmt die Zugehörigkeit eines Objekts zu einer Klasse unter der Berücksichtigung der k nächsten Nachbarn nach dem Mehrheitsprinzip. Das heißt, dass ein Objekt zu der Klasse hinzugefügt wird, welche in der Nachbarschaft am stärksten Vertreten ist. Um die Abstände zweier Objekte zu ermitteln verwendet man häufig den Euklidischen Abstand. Es gibt aber auch Alternativen, wie z.B. die Manhatten-Metrik, die unter Umständen besser funktionieren. Eine häufig verwendete Methode, um ein geeignetes k zu finden, ist, den Algorithmus mit verschiedenen Werten für k auszuführen und dann den geeignetsten Wert zu verwenden. Allgemein zu erwähnen ist, dass im Gegensatz zur Darstellung für dieses Verfahrens anstelle eines zwei-dimensionalen Raums auch ein multi-dimensionaler Raum verwendet werden kann.
Support Vector Machine
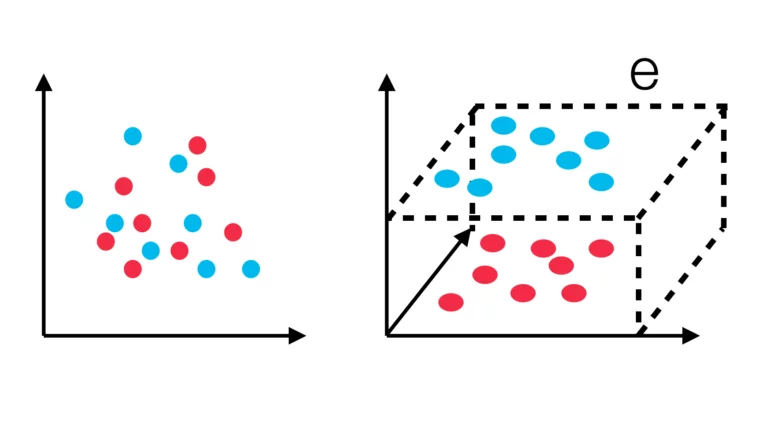
Die Support Vector Machine stellt jedes Objekt als Vektor in einem n-dimensionalen Vektorraum dar. Dies ist wichtig, damit sich die Vektoren auch für nicht lineare Trainingsdaten durch eine Ebene trennen lassen. Um die verschiedenen Vektoren voneinander linear zu trennen, wählt man eine Hyperebene so, dass die Vektoren möglichst weit von dieser entfernt sind. Weitere Objekte werden dann in Abhängigkeit zu ihrer Position im Hyperraum klassifiziert. Im oben gezeigten Beispiel, werden die ursprünglichen zwei dimensionalen Vektoren in einen drei dimensionalen Raum abgebildet. Sofort ersichtlich lassen sich die Vektoren im zwei-dimensionalen Raum nicht linear trennen. Im Gegensatz dazu ist es im drei-dimensionalen Raum möglich, eine Ebene „e“ so zu legen, dass die beiden Mengen linear trennenbar sind.
Neuronale Netze
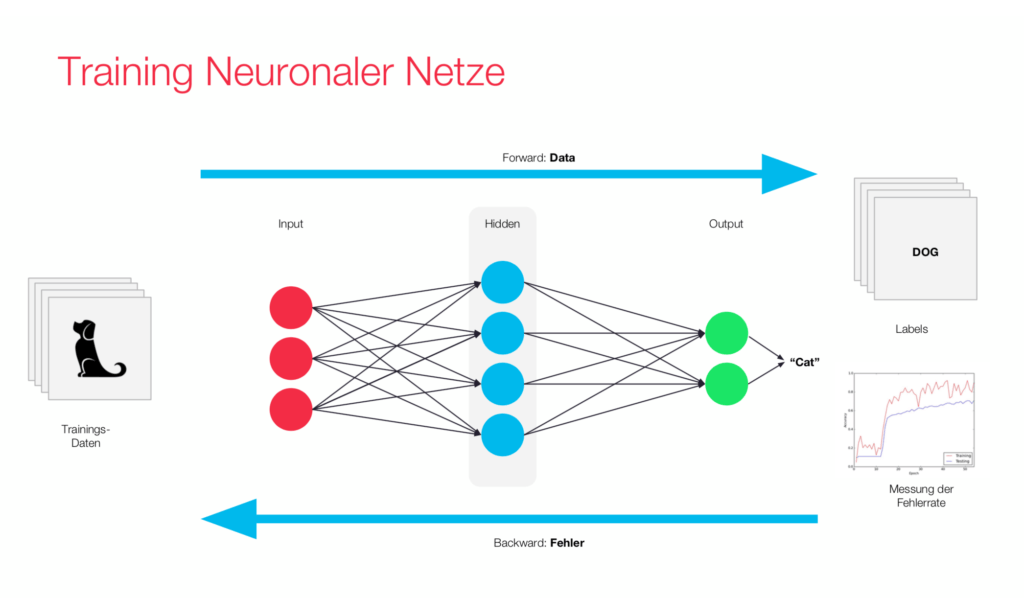
Mit neuronalen Netzen ist es möglich Objekte zu klassifizieren. Wenn genügend Trainingsdaten vorhanden sind, erreichen diese in der Regel zum Teil sehr gute Ergebnisse im Vergleich zu anderen Verfahren. Ein gutes Beispiel dafür ist die Objekterkennung in Bildern. Eben diese guten Ergebnisse sorgten für einen großen Hype um neuronale Netze. Der Blogeintrag zu neuronalen Netzen geht ausführlich auf dieses Verfahren ein.
Herausforderungen der Klassifizierung
Bei der Wahl des passenden Klassifikators muss man folgende Eigenschaften berücksichtigen:
Genauigkeit
Die Genauigkeit der Klassifizierung hängt von den verwendeten Regeln ab. Dabei muss man bedenken, dass die Genauigkeit auf den Trainingsdaten und auf den nicht trainierten Daten meist unterschiedlich ausfällt. So kann es durchaus sein, dass ein Machine Learning Modell, perfekte Ergebnisse für die Trainingsdaten erzeugt. Es kann aber sein, bei der Klassifizierung von neuen Daten nur eine schlechte Genauigkeit erzielt wird. Dabei bestimmt das Verhältnis der richtig klassifizierten Objekte die Genauigkeit des Modells.
Geschwindigkeit
Unter Umständen ist die Geschwindigkeit eines Klassifikators ein wichtiges Verwendungskriterium. So kann es sein, dass ein Klassifikator eine 90%ige Genauigkeit in einem hundertstel der Zeit erreicht, im Vergleich zu einem Klassifikator, der eine 95%ige Genauigkeit erreicht. So kann es sinnvoll sein auf Genauigkeit zu verzichten, wenn man dafür eine Verbesserung der Geschwindigkeit erreicht.
Erklärbarkeit
Es könnte wichtig sein, dass leicht nachzuvollziehen ist, wie ein Klassifikator zu seinem Ergebnis kommt. Vor allem, damit Menschen die mit dem Modell arbeiten, Vertrauen in dieses haben wie zum Beispiel bei wichtigen Unternehmensentscheidungen.
Anwendung
Die Klassifikation bietet viele spannende Anwendungsfelder wie z.B. in der Computer Vision, bei der es darum geht, einem Computer ein visuelles Verständnis der Welt zu vermitteln, was wiederum Verwendung in verschiedenen Bereichen wie beispielsweise bei selbstfahrenden Autos findet. Ebenfalls ermöglicht Machine Learning die Klassifikation von Spam E-Mails oder auch den Einsatz in der Medizin wie bei der frühzeitigen Erkennung von Krankheiten.


