
Diesen Beitrag zusammen mit dem Code haben wir auch als Jupyter Notebook veröffentlicht..
In diesem Beitrag zeigen und vergleichen wir verschiedene Verfahren zum Clustering in Python. Unter Clustering versteht man das Zusammenfassen verschiedener Objekte zu Gruppen aus ähnlichen Objekten. Beispielsweise die Segmentierung von verschiedenen Käufergruppen im Einzelhandel.
Beim Clustering werden die einzelnen Eigenschaften eines Objekts mit den Eigenschaften anderer Objekte in einem Vektorraum verglichen. Ziel ist es in diesem Vektorraum auf Zusammenhänge zu schließen, mit denen sich einzelnen Gruppen der Objekte in einem Datensatz bilden lassen. Die einzelnen Vektoren, die dabei für die verschiedenen Eigenschaften eines Objekts stehen, werden auf ihre Nähe zu den Vektoren anderer Objekte hin in Cluster eingeteilt. Um die Nähe zweier Vektoren zu bestimmen ist prinzipiell jede Metrik zulässig. Meistens wird jedoch die euklidische Distanz, oder die quadrierte euklidische Distanz (L2-Norm) verwendet.
Häufig werden Unsupervised Learning Modelle für das Clustering verwendet. Dies bietet den Vorteil, dass keine bzw. nur wenige Annahmen über die zu findenden Cluster von vorneherein zu treffen sind. In diesem Beitrag gehen wir ausschließlich auf solche Modelle ein, da diese am weitesten verbreitet sind. Der Nachteil den diese Ansätze mit sich bringen liegt darin, Grundlagen zur Beurteilung des Ergebnisses zu finden, um auf diesen die einzelnen Verfahren zu vergleichen und zu bewerten.
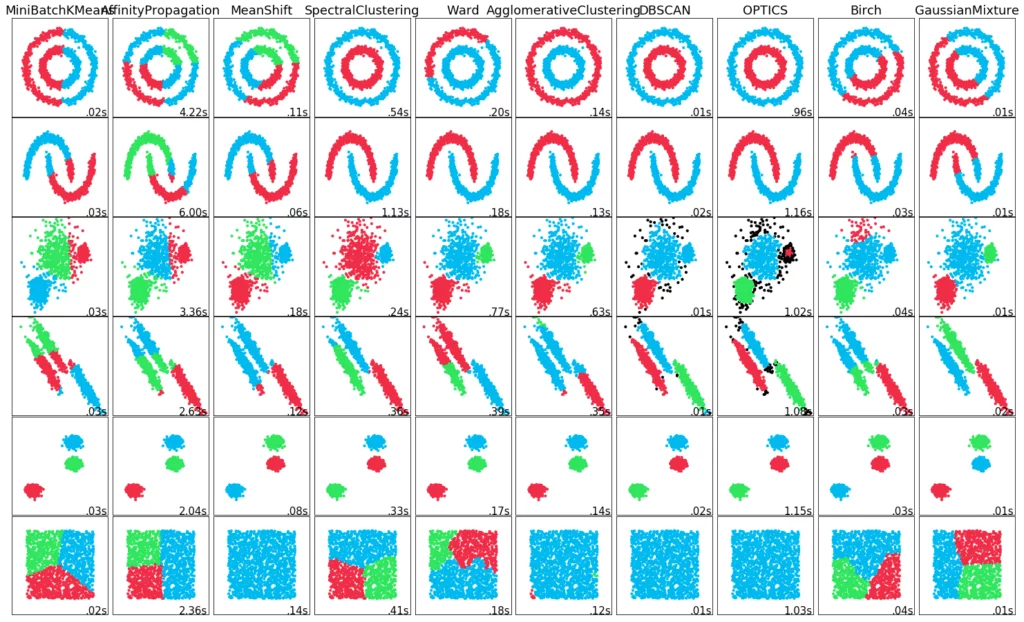
Eine Zusammenfassung der unterschiedlichen Clusteringverfahren findest Du in unserem Blog.
Validierung von Clusteringergebnissen
Es ist sehr schwer ein Clusteringergebnis objektiv zu bewerten, da ein Clusteringalgorithmus in eigener Verantwortung Cluster finden soll. Gäbe es bereits eine Einteilung der Objekte eines Datensatzes in Gruppen, wäre das Clustering überflüssig. Da diese Gruppeneinteilung aber nicht bekannt ist, ist es schwer zu sagen, ob ein Cluster gut gewählt ist oder nicht. Dennoch gibt es einige Methoden, mit denen sich zumindest bessere von schlechteren Clusteringergebnissen unterscheiden lassen. Nachfolgend haben wir eine Liste mit den gängigsten Methoden aufgestellt.
Elbow-Kriterium
Das Elbow-Kriterium eignet sich, um bei einem k-means Clustering die optimale Anzahl von Clustern zu bestimmen. Dabei trägt man in einem Diagramm auf der x-Achse die Anzahl der Cluster auf und auf der y-Achse die Summe der quadrierten Abweichungen der einzelnen Punkte zum jeweiligen Clusterzentrum. Falls auf dem Diagramm ein Knick erkennbar sein sollte, ist dieser Punkt die optimale Anzahl an Clustern. Denn ab diesem Punkt sinkt die Aussagekraft der einzelnen Cluster, da sich die Summe der quadrierten Abweichungen nur noch leicht verändert.
Gap Statistic
Die Gap Statistic vergleicht die Abweichungen der einzelnen Objekte innerhalb eines Clusters im Bezug zu dem jeweiligen Zentrum. Dabei wird die Verteilung der Objekte mit einer zufälligen Verteilung verglichen. Je weiter dabei die Verteilung in Abhängigkeit zu der Anzahl der Cluster von der zufälligen Verteilung entfernt ist, desto besser ist die jeweilige Anzahl an Clustern.
Calinski-Harabasz Index
Der Calinski-Harabasz Index setzt die Separierung und Kompaktheit der Cluster in ein Verhältnis zueinander. Somit wird die Varianz der Quadratsummen der Abstände einzelner Objekte zu ihrem Clusterzentrum durch die Quadratsumme der Distanz zwischen den Clusterzentren und dem Mittelpunkt der Daten eines Clusters geteilt. Ein gutes Clusteringergebnis hat dabei einen hohen Calinski-Harabasz Index Wert.
Silhouettenmethode
Die Silhouettenmethode vergleicht den durchschnittlichen Silhouettenkoeffizienten unterschiedlicher Clusteranzahlen. Der Silhouettenkoeffizient gibt dabei an, wie gut die Zuordnung eines Objekts zu seinen beiden nächsten Clustern A und B ausfällt. Dabei ist der Cluster A der Cluster zu dem das Objekt zugeordnet wurde.
Der Silhouettenkoeffizient berechnet sich, in dem die Differenz des Abstands des Objekts zum Cluster B zu dem Abstand des Objekts zum Cluster A gebildet wird. Diese Differenz wird anschließend mit der maximalen Distanz des Objekts zu Cluster A und B gewichtet. Dabei kann das Ergebnis S(Objekt) zwischen -1 und 1 liegen. Falls S(Objekt) < 0 liegt das Objekt näher an Cluster B als an A. Demnach kann das Clustering verbessert werden. Falls S(Objekt) ≈ 0 Dann liegt das Objekt mittig der beiden Cluster. Somit ist das Clustering wenig aussagekräftig. Je weiter sich S(Objekt) an 1 annähert desto besser ist das Clustering für dieses. Silhouettenmethode wird nach der Anzahl an Clustern gesucht, für die der durchschnittliche Silhouettenkoeffizient am höchsten liegt.
Clustering
Zunächst werden wir uns einen Datensatz generieren um die Daten in Cluster einzuordnen.
Datensatzgenerierung
Unseren Datensatz generieren wir so, dass er aus insgesamt 80 zweidimensionalen Punkten besteht, die in einem festgelegten Radius zufällig um drei Punkte erzeugt werden. Dafür verwenden wir die Methode “make_blobs” aus scikit-learn.
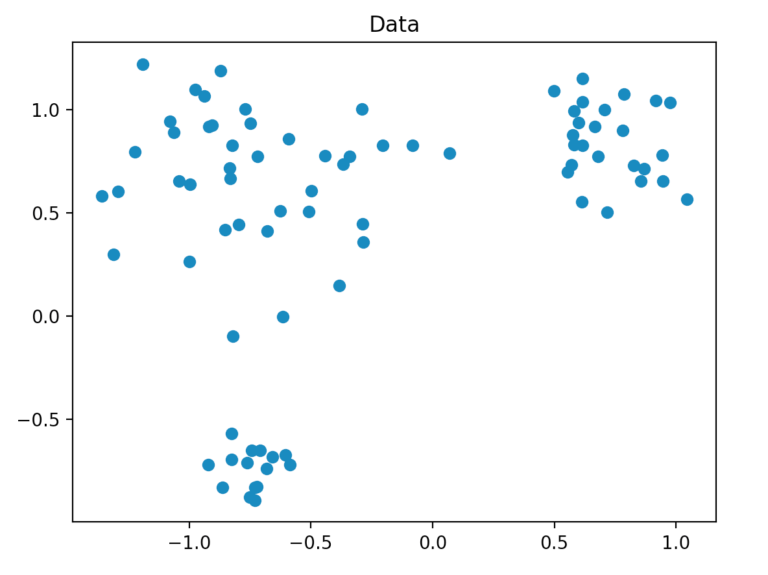
Clusteringverfahren
Nachdem wir unsere Daten nun generiert haben, können wir mit dem eigentlichen Clustering beginnen. Dafür verwenden wir die Verfahren k-means, DBSCAN, HDBSCAN und OPTICS. Mit Ausnahme von HDBSCAN entstammen die Verfahren der scikit-learn Bibliothek. Für das HDBSCAN Verfahren gibt es aber ebenfalls eine vorgefertigte Bibliothek auf die wir zurückgegriffen haben. Dabei zählt k-means zu den partitionierenden Verfahren und die übrigen Verfahren werden als dichtebasierte Verfahren bezeichnet. Im Grunde sind HDBSCAN und OPTICS lediglich verbesserte Versionen des DBSCAN. Mit der Methode “fit_predict” von scikit-learn bestimmen wir mit jedem Modell die Zugehörigkeit der Punkte zu einem Cluster.
An dieser Stelle stellen wir die verwendeten Verfahren kurz vor und erläutern ihre Funktionsweise.
k-means
Das k-means Verfahren teilt den Datensatz in k Teile auf. Dies geschieht, in dem die Summe der quadratischen Abweichungen der einzelnen Punkte von den Clusterzentren minimiert wird. Problematisch an diesem Verfahren ist einerseits, dass bereits im Voraus die Anzahl der Cluster zu bestimmen ist, andererseits kann das Verfahren mit Datensätzen mit variierenden Dichten und Formen zum Teil nur schlecht umgehen. Dadurch ist es auf realen Datensätzen oftmals nicht bestens geeignet. Ebenfalls kann das Verfahren keine Noise Objekte, also Objekte die weit von einem Cluster entfernt liegen und diesem eigentlich nicht mehr zuzuordnen sind, nicht als solche erkennen.
DBSCAN
DBSCAN steht für “Density-Based Spatial Clustering of Applications with Noise”. Die Grundannahme des DBSCAN Algorithmus besteht darin, dass Objekte eines Clusters dicht zusammenliegen. Es werden 3 Arten von Objekten unterschieden:
- Kernobjekte sind Objekte die selbst dicht sind.
- Dichte-erreichbare Objekte sind Objekte, die selbst nicht dicht, aber von einem Kernobjekt erreichbar sind.
- Noisepunkte sind Objekte die weder dicht noch dichte-erreichbar sind.
Dabei wird ein Parameter epsilon und ein Parameter minPoints festgelegt. Epsilon bestimmt dabei die Distanz, ab wann ein Punkt von einem zweiten Punkt erreichbar ist, nämlich dann, wenn ihr Abstand kleiner als epsilon ist. MinPoints legt fest, ab wann ein Objekt dicht ist, also wie viele Objekte innerhalb des Abstands epsilon um einen Punkt liegen müssen.
HDBSCAN
HDBSCAN steht für “Hierarchical Density-Based Spatial Clustering” und basiert auf dem DBSCAN Algorithmus. Er erweitert diesen, indem er den DBSCAN Algorithmus in einen hierarchischen Clusteringalgorithmus überführt. Deswegen benötigt er keinen Abstand epsilon zur Bestimmung der Cluster. Damit ist es möglich Cluster unterschiedlicher Dichte zu finden und somit eine große Schwachstelle von DBSCAN zu beheben.
HDBSCAN funktioniert dabei, indem zunächst eine Zahl k festgelegt wird. Mit dieser wird bestimmt, wie viele Nachbarschaftsobjekte bei der Bestimmung der Dichte eines Punkts betrachtet werden. Hierin besteht ein entscheidender Unterschied im Vergleich zum DBSCAN Algorithmus. DBSCAN sucht in der gegebenen Distanz epsilon nach Nachbarn und HDBSCAN sucht nach der Distanz, ab der k Objekte in der Nachbarschaft liegen.
Nach dieser Zahl k wird die Kerndistanz für jeden Punkt bestimmt. Diese ist die kleinste Distanz, mit der k Objekte erreicht werden können. Außerdem wird eine Erreichbarkeitsmetrik eingeführt. Diese ist definiert als der größte Wert von entweder der Kerndistanz des Punktes A, der Kerndistanz des Punktes B, oder der Distanz von Punkt A zu Punkt B. Mit dieser Erreichbarkeitsmetrik wird anschließend ein minimaler Spannbaum gebildet. Mit Hilfe dieses Spannbaums wird nun die namens gebende Hierarchie gebildet.
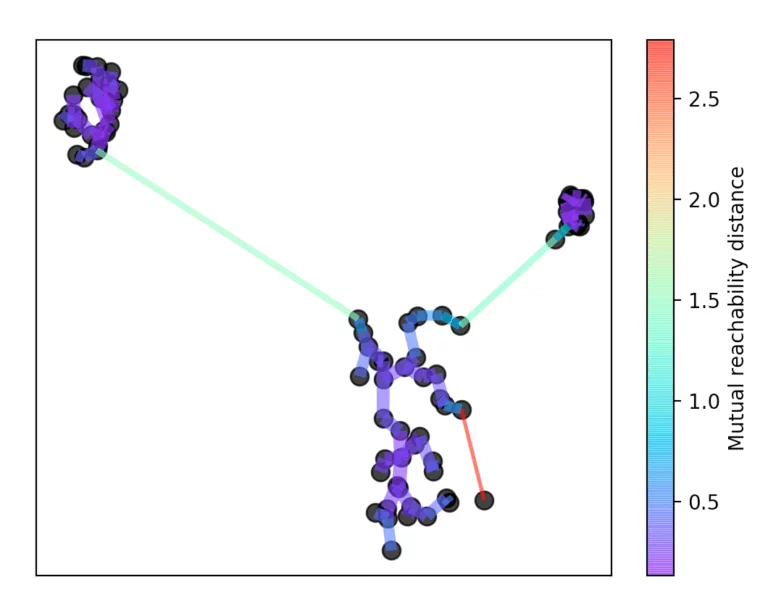
Dazu wird immer die längste Kante aus dem Baum entfernt. Anschließend wird die Hierarchie zusammengefasst, indem in Abhängigkeit zur Distanz die einzelnen Punkte aus der Hierarchie herausfallen.
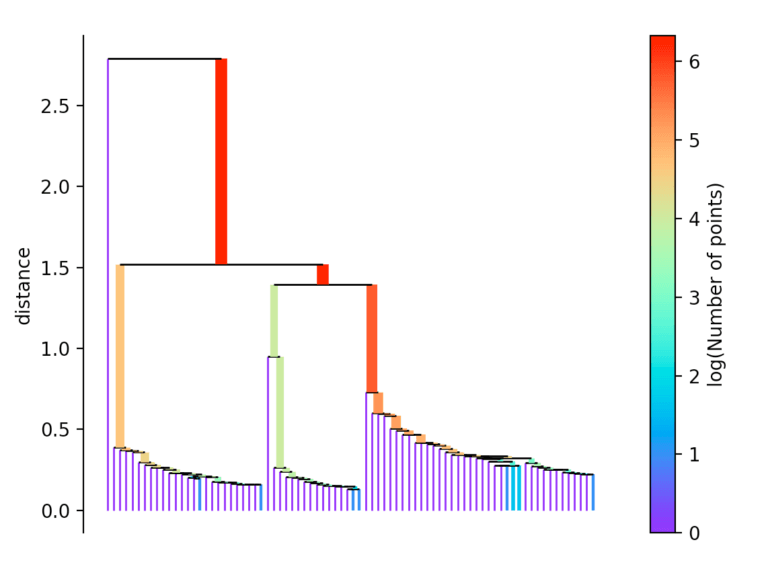
Falls mehr als zu Beginn definierte min_cluster_size Punkte bei einer Distanz herausfallen, bilden diese einen neuen Teilbaum. Anschließend wählt das Verfahren die Cluster aus, die die größte Stabilität aufweisen. Die Stabilität eines Cluster berechnet sich, in dem man die Summe der Kehrwerte der Distanz, ab welcher ein Punkt aus einem Cluster fällt, für aller Punkte eine Clusters berechnet. Das heißt liegen viele Punkte nahe am Clusterzentrum hat der Cluster eine hohe Stabilität. Auf dem Bild erkennbar an einer großen Fläche.
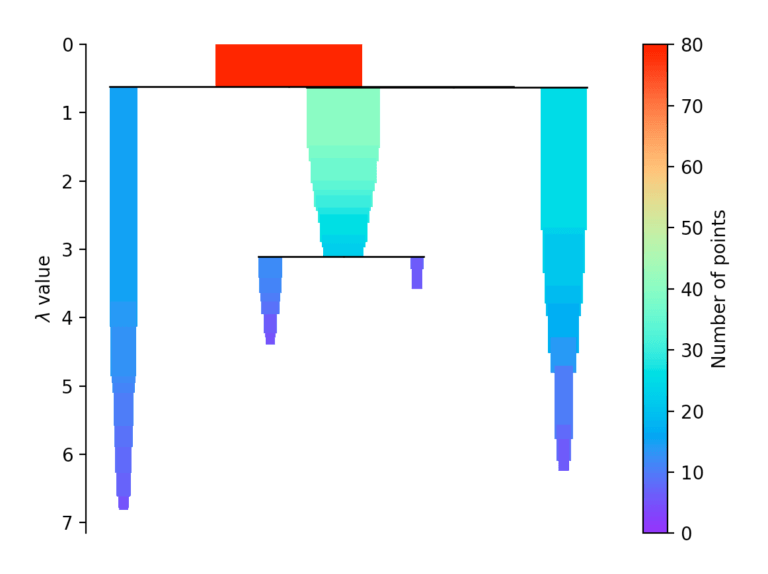
Auswertung
Für unsere Auswertung haben wir uns entschieden, die Metriken Calinski-Harabasz Index, die Silhouettenmethode und für das k-means Clustering speziell das Elbow Kriterium zu verwenden.
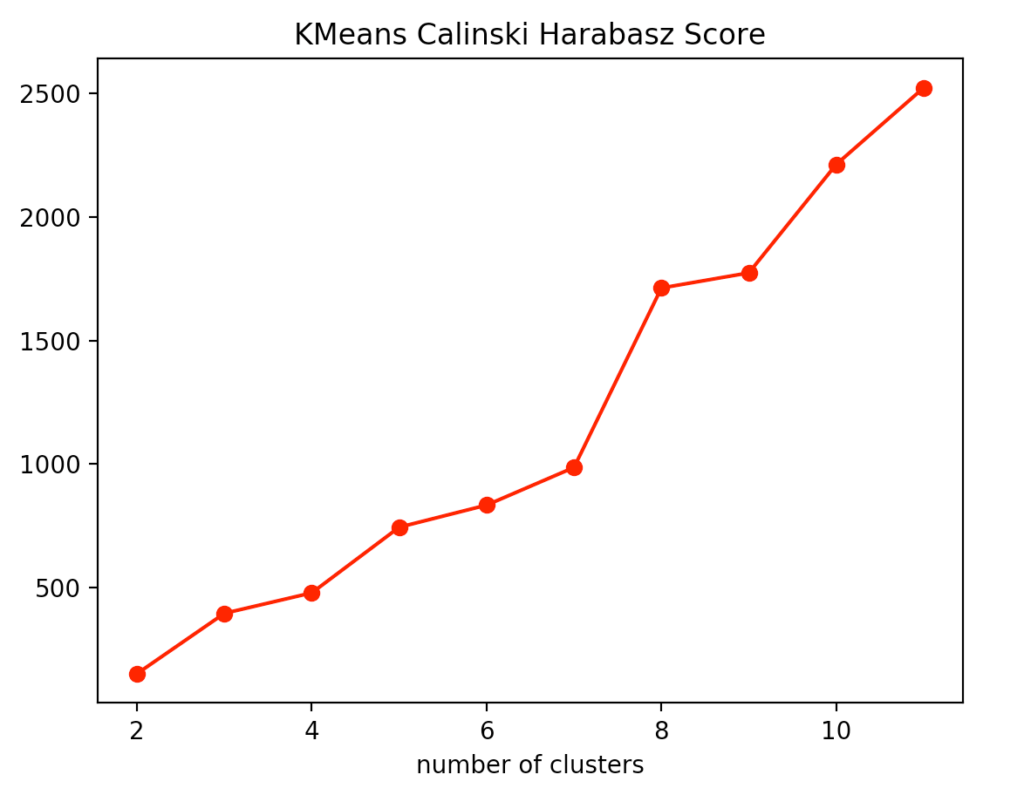
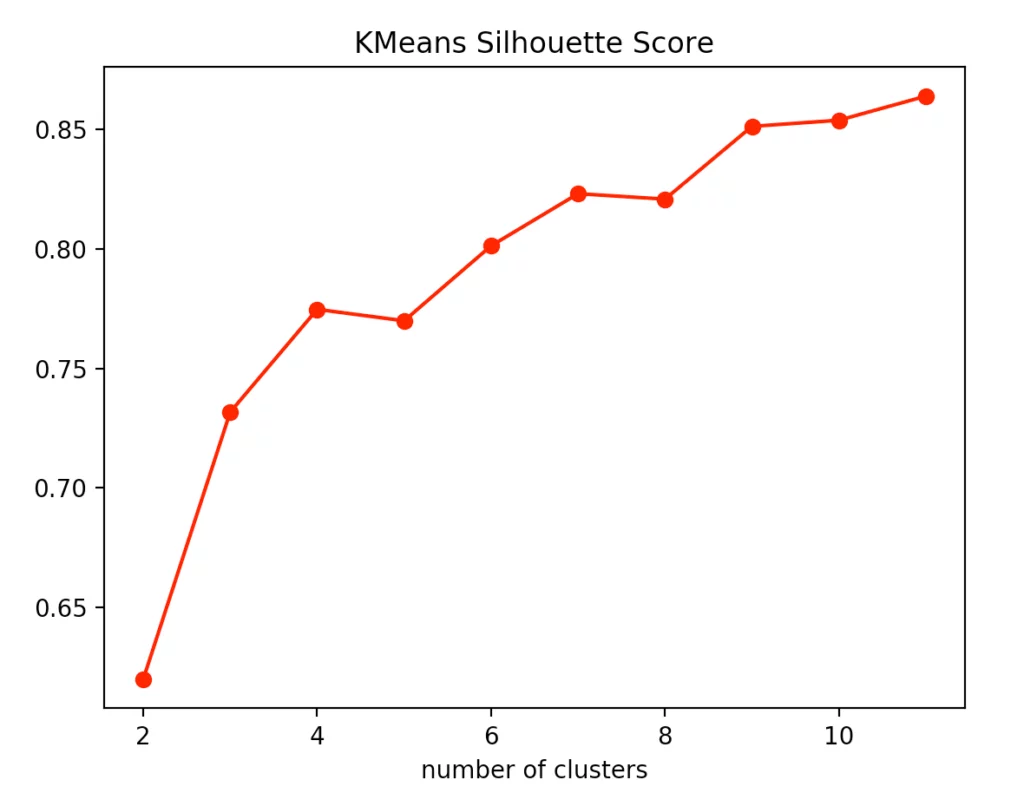
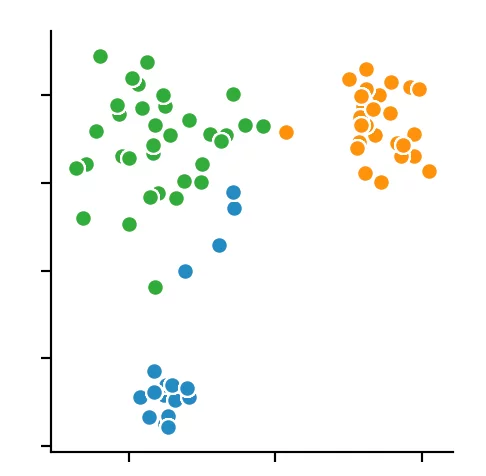
Wenn man sich die einzelnen Metriken für das k-means Clustering anschaut, stellt man fest, dass die optimale Anzahl an Clusterzentren 3 beträgt. Zwar deutet die Silhouettenmethode darauf hin, dass ein vierter Cluster durchaus sinnvoll wäre, allerdings spricht das Elbow Kriterium dagegen, da ein vierter Cluster keinen Knick bildet und somit nur einen sehr bedingten Mehrwert bietet. Nimmt man noch den Calinski-Harabasz Index dazu, erkennt man ebenfalls, dass der vierte Cluster nur einen schwach höheren Score erzielt. Daraus folgern wir, dass drei die optimale Anzahl an Clustern für ein k-means Clustering auf unserem Datensatz ist. Dieses Ergebnis gibt auch Sinn, wenn man bedenkt, dass wir unsere Daten um 3 Punkte generiert haben.
Für die beiden anderen Clusteringverfahren können wir die Anzahl der zu findenden Cluster nicht vorher bestimmen, sondern lediglich die Parameter vorgeben, nach denen die Algorithmen die Cluster finden. So haben wir uns dafür entschieden für das DBSCAN Verfahren die Distanz epsilon festzulegen und lediglich die Anzahl der minPoints zu variieren.
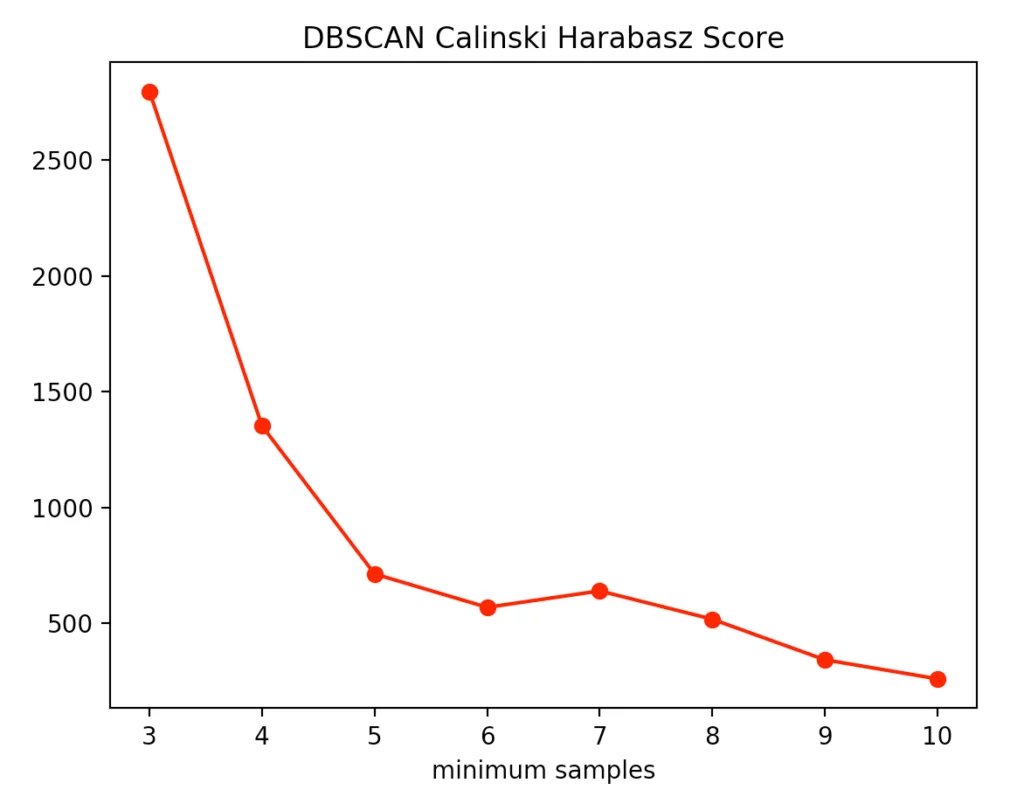
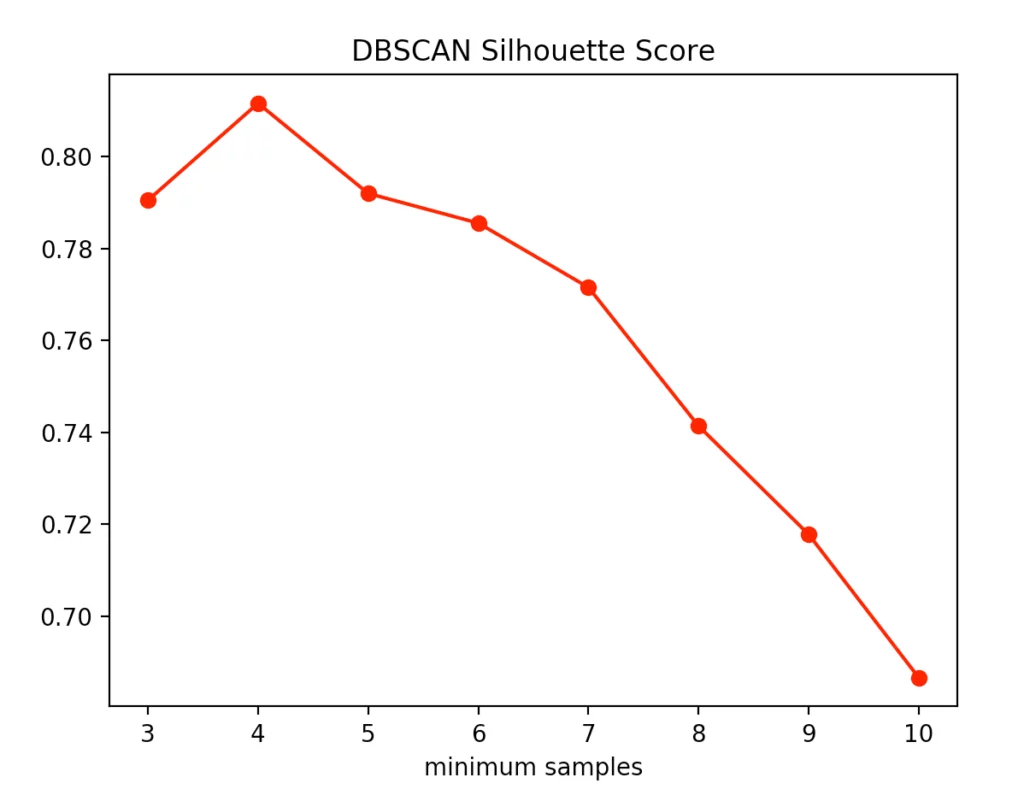
Dabei deutete die Silhouettenmethode auf die Anzahl von vier minPoints hin. Dagegen spricht der Calinski-Harabasz Index dafür nur drei minPoints festzulegen. Da der Unterschied von drei auf vier minPoints in der Silhouettenmethode geringer ausfällt als bei dem Calinski-Harabasz Index, entscheiden wir uns dafür, den Wert auf drei festzulegen. Dabei entsteht folgendes Clustering:
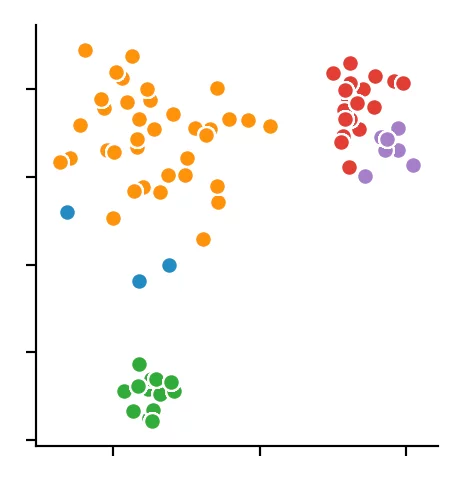
Wir erkennen, dass der Algorithmus sich für 4 Clusterzentren entschieden hat. Dabei wird deutlich, dass der DBSCAN Algorithmus Schwierigkeiten bei unterschiedlich dichten Clustern bekommt.
Beim HDBSCAN Verfahren variieren wir die kleinste Clustergröße. Das ist die Anzahl an Punkten, die bei dem hierarchischen Verfahren nötig ist, dass ein oder mehrere abgetrennte Punkte als neuer Cluster angesehen werden. Hierbei erhalten wir folgende Ergebnisse für den Calinski-Harabasz Index und die Silhouettenmethode.
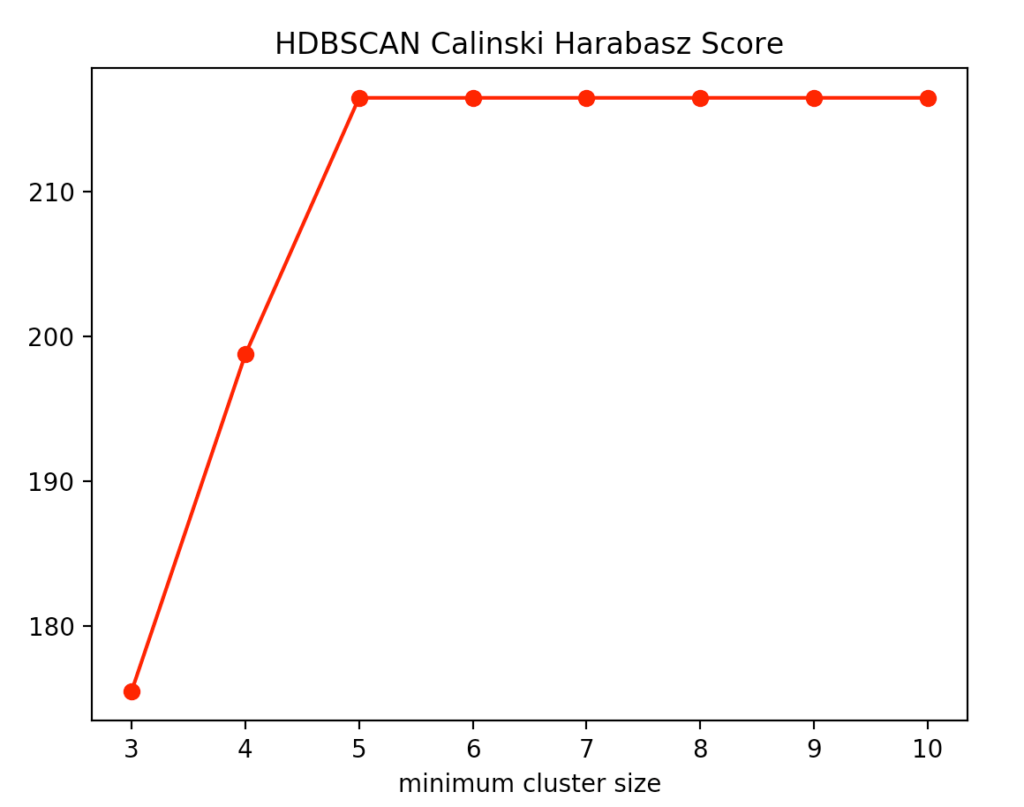
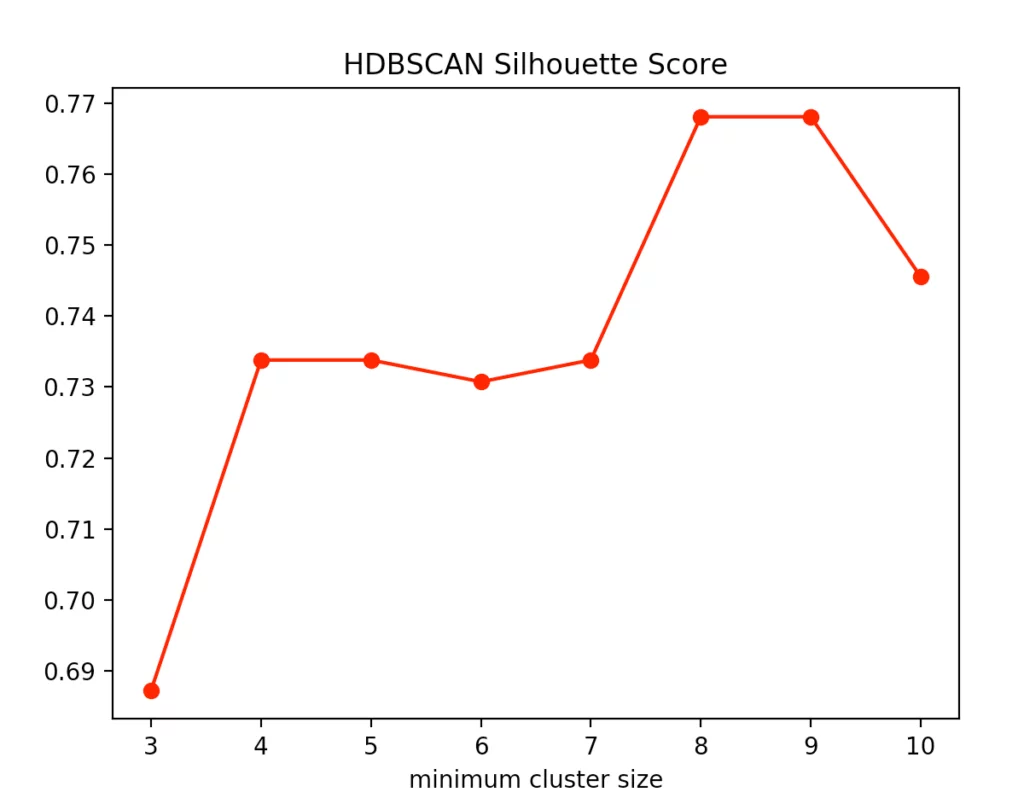
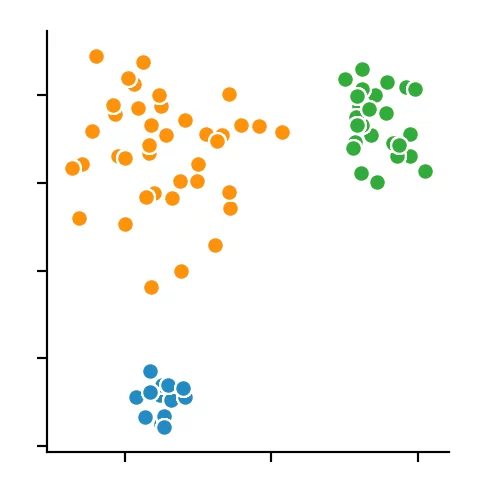
Dabei erkennen wir, dass die optimale Größe zwischen vier und fünf Punkten liegt. Wir entscheiden uns für vier und erhalten folgendes Ergebnis.
Fazit
Es sollte deutlich geworden sein, dass es schwierig sein kann, Clusteringergebnisse auf einem Datensatz auf ihre Richtigkeit einzuordnen. Es gibt viele weitere Verfahren, die ebenfalls unterschiedliche Lösungen hervorgebracht hätten. Die Metriken zur Validierung der Clusteringergebnisse eignen sich im Einzelnen nur bedingt und so ist es stets sinnvoll eine Vielzahl von Metriken zur Hilfe zu ziehen und diese miteinander zu vergleichen, um somit den geeignetsten Algorithmus für den jeweiligen Anwendungsfall finden zu können und die Parameter bestens abstimmen zu können. Trotz der genannten Schwächen ermöglichen Clusteringverfahren unter Berücksichtigung der genannten Punkte, auch höher dimensionale Daten in Gruppen einzuteilen.


