
Beim Machine Learning geht es um die Verwendung und Entwicklung von Computersystemen, die in der Lage sind, zu lernen und sich anzupassen, ohne dabei explizite Anweisungen zu befolgen. Dafür verwenden sie Algorithmen und statistische Modelle, um Muster in Daten zu analysieren und daraus eigenständig Rückschlüsse für zukünftige Analysen zu ziehen. Die Ergebnisse eines solchen Modelltrainings können in weiterer Folge für die Erstellung von Vorhersagen (mit unbekannten Daten) verwendet werden.
Ein Modell ist eine destillierte Darstellung dessen, was ein maschinelles Lernsystem gelernt hat. Ein solches ist mit mathematischen Funktionen vergleichbar:
- Es nimmt eine Anfrage in Form von Eingabedaten entgegen,
- trifft eine Vorhersage zu diesen
- und liefert aufgrund von dieser wiederum eine Antwort auf eine bestimmte Fragestellung.
Das Programmieren und Trainieren (mit bekannten Datensätzen) des Algorithmus ist dabei der erste wichtige Schritt. Die Überprüfung, ob er auch für unbekannte Datensätze - und damit in der Praxis - angewandt werden kann, der zweite. Denn nur durch diese Überprüfung wissen wir anschließend, ob das Modell tatsächlich funktioniert und wir seinen Vorhersagen vertrauen können. Ansonsten könnte es sein, dass der Algorithmus die Daten, mit denen er gefüttert wird, lediglich auswendig lernt (Overfitting / Überanpassung) und in weiterer Folge nicht in der Lage ist, zuverlässige Vorhersagen für ihm unbekannte Datensätze zu treffen.
In diesem Beitrag zeigen wir dir zwei der häufigsten Probleme der Modellvalidierung auf: Das Overfitting und Underfitting. Sowie, wie du diese vermeiden kannst.
Inhaltsverzeichnis:
- Was ist Modellvalidierung (und zu was dient sie)?
- Was bedeutet Overfitting (und Underfitting)?
- Wie kann Overfitting und Underfitting reduziert werden?
- Welche Methoden zur Modellvalidierung gibt es?
1. Was ist Modellvalidierung (und zu was dient sie)?
Definition: Das Verfahren der Modellvalidierung beschreibt den Vorgang, ein statistisches oder datenanalytisches Modell auf seine Performance hin zu überprüfen.
Sie ist ein wesentlicher Bestandteil des Modellentwicklungsprozesses und hilft dabei, das Modell zu finden, das Deine Daten am besten repräsentiert. Außerdem dient sie dazu abzuschätzen, wie gut dieses in der Zukunft funktionieren wird. Diese Bewertung, mit den für das Training verwendeten Datensätzen durchzuführen, ist nicht zielführend, da dadurch leicht überoptimistische und überangepasste Modelle erzeugt werden können (Overfitting).
2. Was bedeutet Overfitting (und Underfitting)?
Overfitting (deutsch: „Überanpassung“) bezieht sich auf ein Modell, das die Trainingsdaten zu gut modelliert. Sprich, dass es zu speziell an seinen Trainingsdatensatz angepasst ist.
Überanpassung tritt dann auf, wenn ein Modell die Details und das Rauschen (zufällige Schwankungen) in den Trainingsdaten in einem Ausmaß erlernt, das sich negativ auf seine Leistung bei neuen / unbekannten Daten auswirkt. Das zeigt sich dadurch, dass das Rauschen aufgegriffen und als Konzept gelernt wird. Das Problem hiermit ist, dass diese Konzepte nicht auf neue Daten zutreffen und sich somit negativ auf die Generalisierungsfähigkeit (Anwendbarkeit auf jeglichen unbekannten Datensatz) des Modells auswirken.
Niedrige Fehlerraten und eine hohe Varianz sind starke Indikatoren für eine Überanpassung. Sie ist wahrscheinlicher bei nichtparametrischen und nichtlinearen Modellen, die beim Lernen einer Zielfunktion mehr Flexibilität haben. Daher enthalten viele nichtparametrische Algorithmen für maschinelles Lernen Parameter oder Techniken, um einzuschränken, wie viele Details das Modell erlernen soll.
Entscheidungsbäume sind z. B. ein nichtparametrischer Algorithmus für maschinelles Lernen, der sehr flexibel ist. Bei diesen kommt es deshalb häufig zu einer Überanpassung der Trainingsdaten. Dieses Problem kann jedoch gelöst werden, indem ein Baum nach dem Lernen beschnitten wird, um einen Teil der Details zu entfernen, die er während des Lernprozesses aufgenommen hat.
Außerdem tritt Overfitting häufig dann auf, wenn der Trainingsdatensatz relativ klein und das Modell gleichzeitig relativ komplex ist. Ein zu komplexes Modell kann die Trainingsdaten nämlich schnell zu genau abbilden - umgekehrt bildet ein zu simples Modell die Trainingsdaten schnell zu ungenau ab (hier spricht man von Underfitting / Unteranpassung).
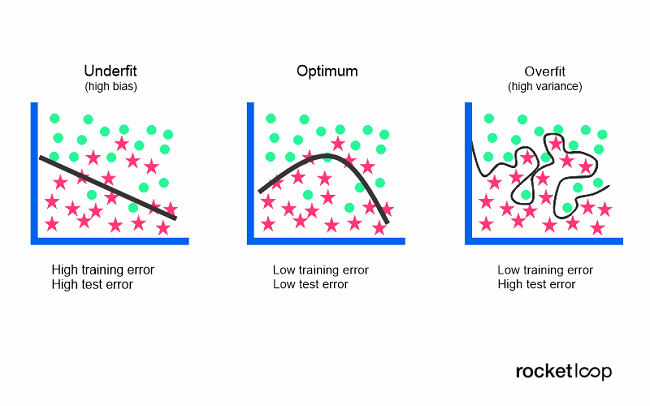
Ein zu einfaches Datenmodell ist in der Regel nicht in der Lage, die Beziehung zwischen den Eingabe- und Ausgabevariablen genau zu erfassen. Dadurch entsteht eine hohe Fehlerrate - sowohl mit den Trainingsdaten als genauso mit unbekannten Datensätzen. Eine hohe Verzerrung / Fehlerrate in Kombination mit einer geringen Varianz sind in weiterer Folge starke Indikatoren für eine Unteranpassung.
Da dieses Verhalten schon während dem Training gut zu sehen ist, sind unterangepasste Modelle in der Regel leichter zu identifizieren als überangepasste. Die Lösung für das Underfitting kann mehr Trainingszeit, ein Mehr an Eingabefunktionen oder weniger Regularisierung sein - doch dazu mehr im nächsten Abschnitt.
Sowohl Over- als auch Underfitting führen zu einer zu geringen Allgemeingültigkeit eines Modells. Falls ein Modell jedoch nicht zuverlässig auf unbekannte Daten angewandt werden kann, dann kann es allerdings genauso wenig für Klassifizierungs- oder Vorhersageaufgaben verwendet werden. Die generalisierte Anwendung eines Modells auf neue Daten ist letztendlich das, was es uns ermöglicht, Algorithmen für das maschinelle Lernen zu verwenden, um Vorhersagen zu treffen und Daten zu klassifizieren.
Die Herausforderung ist es also, das Modell zwar einerseits so einfach wie möglich, jedoch andererseits nicht zu einfach, zu halten. Ein perfektes Modell - das heißt eines, bei dem es weder zu Over- noch zu Underfitting kommt - ist nahezu unmöglich zu erstellen. Es gibt jedoch verschiedene Methoden und Werkzeuge, mit welchen diese negativen Effekte mit hoher Wahrscheinlichkeit ausgeschlossen werden können. Welche das sind, erfährst du im nächsten Kapitel.
3. Wie kann Overfitting und Underfitting reduziert werden?
Um beim Training eines Modells Over- und Underfitting von vornherein möglichst weitgehend auszuschließen gibt es verschiedene Methoden. Die wichtigsten von diesen haben wir dir im Folgenden aufgeführt.
Overfitting beim Machine Learning verhindern:
a) Kürzere Trainingszeit (Early Stopping): Bei dieser Methode brichst du das Training ab, bevor das Modell zu viele Details (inklusive dem Rauschen) des Datensatzes auswendig lernt. Bei diesem Ansatz besteht allerdings die Gefahr, dass der Trainingsprozess zu früh gestoppt wird - was wiederum zu dem gegenteiligen Problem der Unteranpassung führt. Den "Sweet Spot" zwischen Underfitting und Overfitting zu finden, ist somit das ultimative Ziel.
b) Mit mehr Daten trainieren: Das Erweitern des Trainingssatzes um mehr Daten kann die Genauigkeit des Modells erhöhen, indem es ihm mehr Möglichkeiten bietet, die maßgebliche Beziehung zwischen den Eingabe- und Ausgabevariablen herauszufiltern. Allerdings ist dies nur dann eine effektive Methode, wenn du ausschließlich saubere und aussagekräftige Daten einspeist. Andernfalls fügst du dem Modell nur ein unnötiges Mehr an Komplexität hinzu, was schlussendlich erst Recht zu einer Überanpassung führt.
c) Datenerweiterung: Während es theoretisch das Beste ist, lediglich saubere und aussagekräftige Trainingsdaten anzuwenden, werden manchmal gezielt verrauschte Daten hinzugefügt, um ein Modell stabiler zu machen. Diese Methode sollte jedoch sparsam (sowie vor allem nur von erfahrenen Anwendern) eingesetzt werden.
d) Merkmalsauswahl: Dabei identifizierst du die wichtigsten Merkmale der Trainingsdaten, um anschließend die irrelevanten - und damit überflüssigen - eliminieren zu können. Dies wird häufig mit einer Reduzierung der Dimensionen verwechselt, ist aber ein anderer Ansatz. Beide Methoden helfen dir jedoch dabei ein Modell zu vereinfachen, um den dominanten Trend in den Daten zu ermitteln.
e) Normalisierung: Diese hängt mit dem vorherigen Punkt der Merkmalsauswahl zusammen, da sie dazu dient, festzulegen, welche Merkmale eliminiert werden sollen. Dazu wendest du eine "Strafe" auf die Eingabeparameter mit den größeren Koeffizienten an, wodurch anschließend die Varianz im Modell begrenzt wird. Es gibt eine Reihe von Normalisierungsmethoden (z. B. L1- und Lasso-Regularisierung oder Dropout) - diese haben jedoch alle dasselbe Ziel: Das Rauschen in den Daten zu identifizieren und zu reduzieren.
f) Ensemble-Methoden: Diese bestehen aus einem Satz von Klassifikatoren (wie z. B. Entscheidungsbäumen). Deren Vorhersagen fasst du zusammen, um das günstigste Ergebnis zu ermitteln. Die bekanntesten Ensemble-Methoden sind Bagging und Boosting.
Overfitting beim Machine Learning verhindern:
a) Längere Trainingszeit: So wie eine Verkürzung der Trainingsphase das Overfitting reduziert, reduziert ihre Verlängerung das Underfitting. Wie bereits erwähnt liegt die Herausforderung deshalb darin, die optimale Dauer des Modelltrainings auszuwählen.
b) Merkmalsauswahl: Falls nicht genügend prädiktive Merkmale vorhanden sind, fügst du mehr von diesen - oder welche mit stärkerer Bedeutung - ein. In einem neuronalen Netzwerk könntest du zum Beispiel mehr versteckte Neuronen hinzufügen. Und in einem Wald mehr Bäume. Dadurch verleihst du dem Modell mehr Komplexität, was zu besseren Trainingsergebnissen führt - allerdings nur zu dem Punkt, an welchem wiederum das Overfitting beginnt.
c) Normalisierung abschwächen: Falls du die Methoden zur Normalisierung der Trainingsdaten zu streng anwendest, kann das dazu führen, dass die Merkmale zu einheitlich werden. Dadurch ist das Modell nicht mehr in der Lage, den dominanten Trend zu identifizieren, was zu einem Underfitting führt. Durch die Verringerung der Regulierung kannst du wieder mehr Komplexität und Variation einbringen.
Wie du sehen kannst, gleicht es der Wanderung auf einem schmalen Grat, den Mittelweg zwischen Under- und Overfitting zu finden. Um sicherzugehen, dass bei Deinem Modell keines der beiden Probleme vorliegt, musst du dieses validieren. Es gibt verschiedene Methoden zur Evaluierung von Modellen in der Datenwissenschaft: Die bekannteste davon ist sicherlich die k-fold Cross Validation. Diese - und noch ein paar weitere - wollen wir dir im Folgenden vorstellen.
4. Welche Methoden zur Modellvalidierung gibt es?
Modellbewertungsmethoden werden verwendet, um
- die Passgenauigkeit zwischen Modell und Daten zu beurteilen,
- verschiedene Modelle zu vergleichen (im Zusammenhang mit der Modellauswahl),
- und um vorherzusagen, wie genau die Prognosen (in Verbindung mit einem bestimmten Modell und Datensatz) voraussichtlich sein werden.
Die Validierung dient also dazu, zu zeigen, dass das Modell eine realistische Darstellung des untersuchten Systems ist: Dass es das Systemverhalten mit ausreichender Genauigkeit reproduziert, um die Ziele der Analyse zu erfüllen. Während die Techniken zur Modellverifizierung allgemein sind, solltest du die Vorgehensweise selbst viel spezifischer anlegen. Sowohl für das betreffende Modell - als auch für das System, in dem es angewendet werden soll.
So wie die Modellentwicklung von den Zielen der Studie beeinflusst wird, wird dies auch für die Modellvalidierung gelten. Wir stellen dir an dieser Stelle nur einige wenige der verwendeten Methoden vor - es gibt jedoch noch eine Vielzahl weiterer. Welche du am Ende auswählst, solltest du abhängig von den spezifischen Parametern und Merkmalen des von dir entwickelten Modells machen.
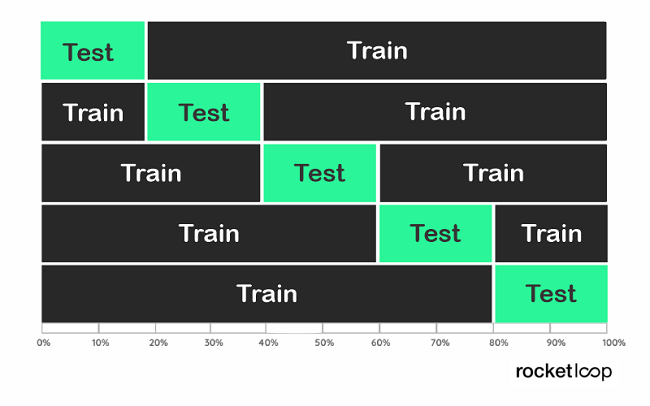
Die Grundlage aller Validierungstechniken ist das Aufteilen des Datensatzes beim Training des Modells. Dies geschieht, um nachzuvollziehen, was passiert, wenn es mit Daten konfrontiert wird, die es noch nie gesehen hat. Deshalb ist eine der einfachsten Methoden der Train-Test-Split.
1. Train-Test-Split
Das Prinzip ist einfach: du teilst deine Daten nach dem Zufallsprinzip in etwa 70% für das Training und 30% für das Testen des Modells auf. Beim Optimieren nach dieser Methode kann es aber wiederum leicht zum Auftreten von Overfitting kommen. Warum? Weil das Modell nach den Hyperparametern sucht, die zu dem spezifischen Train-Test passen, den du durchgeführt hast.
Um dieses Problem zu lösen, kannst du einen zusätzlichen Holdout-Satz erstellen. Dies sind in der Regel 10-20% der Daten, die du für die spätere Validierung reservierst und deshalb weder für das Training noch für den Test verwendest. Nach der Optimierung deines Modells durch den Train-Test-Split kannst du anschließend mit dem Holdout-Set validieren, ob kein Overfitting vorliegt.
Was aber, wenn in einer Teilmenge unserer Daten beispielsweise nur Personen eines bestimmten Alters oder Einkommensniveaus enthalten sind? Ein solcher (ungünstiger) Fall wird als Stichprobenverzerrung bezeichnet. Dabei handelt es sich um einen systematischen Fehler aufgrund einer nicht zufälligen Stichprobe eines Datensatzes (wie der gerade angesprochenen Bevölkerung), der dazu führt, dass einige Datenpunkte (Personen) weniger wahrscheinlich einbezogen werden als andere.
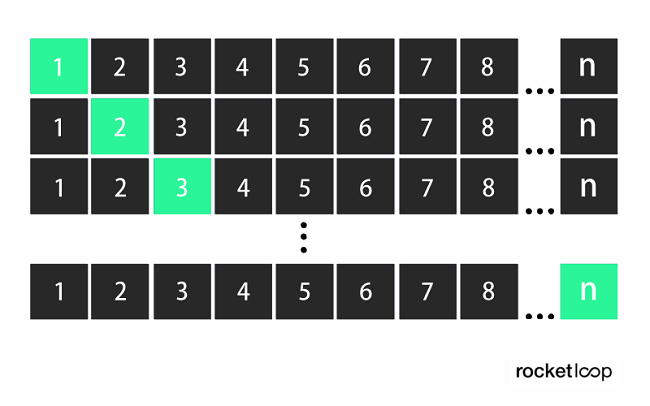
2. k-Fold Cross-Validation (k-Fold CV)
Um die Stichprobenverzerrung zu minimieren, betrachten wir nun den Ansatz der Validierung etwas anders. Was wäre, wenn wir statt eines einzigen Aufteilungsvorgangs viele Aufteilungen vornehmen und für alle Kombinationen von diesen validieren?
An dieser Stelle kommt die k-fold Kreuzvalidierung ins Spiel. Sie
- teilt die Daten in k Foldings auf,
- trainiert dann die Daten auf k-1 Foldings
- und testet auf dem einen Folding, das ausgelassen wurde.
Dies wird für alle Kombinationen durchgeführt und das Ergebnis für die einzelnen Instanzen gemittelt.
Dadurch werden alle Daten sowohl für das Training als auch für die Validierung verwendet. Aber jeder Datenpunkt (jedes Folding) nur einmal für diese. Für k wird typischerweise ein Wert zwischen 5 und 10 gewählt, da hier eine gute Balance zwischen Rechenaufwand und Genauigkeit erreicht wird. Der Vorteil dieser Methode ist, dass du eine relativ variantenfreie Performanceschätzung erhältst. Der Grund dafür ist, dass wichtige Strukturen in den Trainingsdaten nicht ausgeschlossen werden können.
3. Leave-One-Out Cross-Validation (LOOCV)
Die Leave-One-Out-Kreuzvalidierung ist ein Spezialfall der Kreuzvalidierung, bei der die Anzahl der Foldings der Anzahl der Instanzen (Beobachtung) im Datensatz entspricht. Der Lernalgorithmus wird also einmal für jede Instanz angewandt, wobei alle anderen Instanzen als Trainingsset und die ausgewählte Instanz als Single-Item-Testset verwendet wird. Dieses Verfahren ist eng verwandt mit der statistischen Methode der Jack-Knife-Schätzung.
Eine Instanz ist ein Fall in den Trainingsdaten und wird durch eine Anzahl von Attributen beschrieben. Ein Attribut ist wiederum ein Aspekt / Merkmal einer Instanz (z. B. Alter, Temperatur, Luftfeuchtigkeit).
Die Methode ist allerdings rechnerisch sehr aufwendig, da das Modell n-mal trainiert werden muss. Wende sie also nur an, falls die zugrunde liegende Datenmenge klein ist oder du über die Rechenleistung für eine entsprechend große Anzahl an Berechnungen verfügst.
4. Nested Cross-Validation (verschachtelte Kreuzvalidierung)
Bei der Modellauswahl ohne geschachtelte Kreuzvalidierung werden dieselben Daten zum Abstimmen der Modellparameter und zum Bewerten der Modellleistung verwendet, was zu einer optimistisch verzerrten Bewertung des Modells (Overfitting) führen kann. Wir erhalten eine schlechte Schätzung der Fehler in den Trainings- oder Testdaten aufgrund von Informationslecks.
Um dieses Problem zu überwinden, kommt die geschachtelte Kreuzvalidierung (Nested Cross-Validation) ins Spiel, die es erlaubt, den Schritt der Hyperparameter-Abstimmung vom Schritt der Fehlerschätzung zu trennen. Zur Veranschaulichung verschachteln wir einfach einmal zwei k-fache Kreuzvalidierungsschleifen.
- Die innere Schleife für die Hyperparameter-Abstimmung
- sowie die äußere für die Schätzung der Genauigkeit
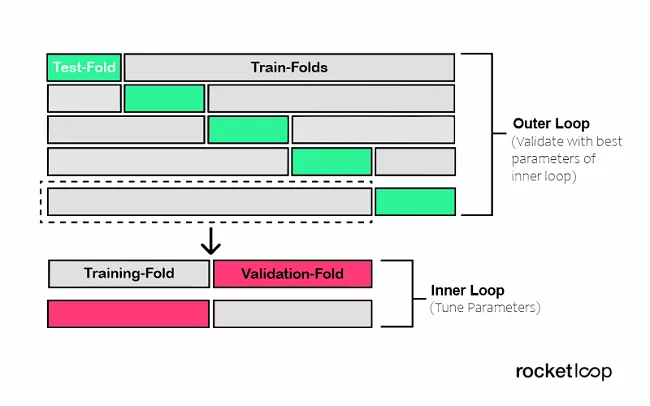
Es steht dir dabei frei, die Kreuzvalidierungsansätze für die innere und äußere Schleife frei zu wählen. So kannst du z. B. die Leave-One-Out-Methode sowohl für die innere als auch für die äußere Schleife verwenden, falls du nach bestimmten Gruppen aufteilen möchtest.
Das war unsere kurze Übersicht über die wichtigsten Methoden zur Validierung eines Modells für das maschinelle Lernen. Damit sind wir auch schon am Ende unseres Beitrags zum Thema “Problemfelder der Modellvalidierung (und deren Lösungen): Overfitting und Underfitting!” angelangt. Wir hoffen, die hier aufgeführten Informationen und Praxisbeispiele sind dir bei Deinem eigenen Softwareentwicklungsprojekt hilfreich.
Falls du dabei doch etwas Unterstützung benötigen solltest, laden wir Dich ein mit uns Kontakt aufzunehmen, um für Deine Softwareentwicklung auf unser erfahrenes Team zurückzugreifen - wir freuen uns auf Deine Nachricht. So sparst du wertvolle Zeit für Deinen Launch, welche du in den Aufbau Deines eigenen Teams investieren kannst, damit du die nächste Produktentwicklung komplett Inhouse stemmst!


